

The SLM Revolution: How Small Models Are Fixing Copilot’s Biggest Flaw


Small Language Models (SLMs) are emerging as one of the most important developments in enterprise AI. While Large Language Models (LLMs) power tools like Microsoft Copilot with impressive reasoning and language capabilities, they also introduce challenges around cost, latency, hallucinations, and scalability. This episode explores why bigger models are not always better and how SLMs can solve many of the problems organizations face when deploying AI at scale.
The discussion explains that many enterprise AI tasks are highly specialized and do not require the full power of a massive LLM. Instead, purpose-built SLMs can be trained or optimized for specific business scenarios, delivering faster responses, lower infrastructure costs, and more predictable outcomes. By narrowing the scope of what a model needs to know, organizations can significantly reduce hallucinations while improving reliability.
The episode also examines how future Copilot architectures are likely to evolve into multi-model ecosystems where SLMs and LLMs work together. Rather than sending every request to a large foundation model, organizations can route routine tasks to smaller specialized models and reserve LLMs for complex reasoning and knowledge synthesis. This approach improves performance, reduces operational costs, and creates more trustworthy AI systems.
Listeners will learn why the next generation of enterprise AI is not about deploying the largest model available, but about selecting the right model for the right task. The future of Copilot may depend less on ever-growing LLMs and more on intelligent orchestration between specialized SLMs, enterprise knowledge sources, and business workflows. By combining speed, efficiency, and accuracy, SLMs could become the missing piece that helps organizations move from AI experimentation to reliable business value.






You see Copilot suggest code, but sometimes it invents packages that do not exist or exposes your sensitive information. Researchers observed that about 30% of packages suggested by ChatGPT were hallucinated. GitHub Copilot collects user interaction data, which creates privacy concerns for developers and enterprises. The slm revolution brings a new wave of ai models. Microsoft’s Phi Family stands out, delivering accurate suggestions and protecting your data. You gain measurable productivity and compliance benefits:
| Impact Type | Measurement |
|---|---|
| Productivity Gains | 5-10% among early users |
| Time Reduction | Complex questions resolved in under 30 seconds |
| Compliance Alignment | Reduced technical support needs while maintaining compliance |
Key Takeaways
- Small Language Models (SLMs) improve accuracy and reduce errors in AI-generated code, making them more reliable than larger models.
- SLMs can be deployed locally, keeping sensitive data secure and helping organizations meet compliance standards.
- Using SLMs can lead to significant cost savings, as they require less expensive hardware and avoid ongoing cloud fees.
- SLMs provide fast responses, enhancing productivity by delivering answers in milliseconds instead of seconds.
- These models help automate tasks like summarizing emails and classifying documents, allowing teams to focus on more important work.
- SLMs reduce privacy risks by limiting data exposure, which is crucial for industries like healthcare and finance.
- The Phi Family of SLMs from Microsoft exemplifies how small models can enhance efficiency and security in various business applications.
- Adopting SLMs can transform workflows, making AI tools more accessible and effective for everyday tasks.
Copilot’s Core Flaw
Main Weakness Explained
You expect Copilot to help you work faster and smarter, but it often struggles with accuracy and privacy. Copilot uses large language models to generate answers, but these models sometimes misrepresent information or invent details. You might see responses that sound convincing but are actually incomplete or even wrong. This happens because the models do not always understand the context or the data they use. You need to double-check facts and review citations, which slows you down.
Privacy is another big concern. Copilot connects to your business data and uses your permissions to access information. If you or your team have too many permissions, Copilot can pull sensitive data without warning. For example, someone with broad access could ask Copilot for confidential details like salaries or performance reviews. Attackers who gain access to these accounts could trigger serious data breaches. The models do not always inherit security labels, so sensitive information might get shared without proper classification.
Here is a table showing some of the most common security flaws in Copilot:
| Security Flaw | Description |
|---|---|
| EchoLeak vulnerability | A zero-click attack exploiting Copilot to pull sensitive data from connected M365 sources. |
| Prompt injection at scale | Malicious instructions hidden in content can manipulate Copilot to retrieve and share data. |
| Agent misconfigurations in Copilot | Misconfigured agents can expose data, run with excessive privileges, or store credentials. |
| Overly permissive data access | Copilot can access everything a user can, risking oversharing of sensitive business data. |
| Security label inheritance issues | Copilot outputs may not inherit security labels, leading to unclassified and improperly shared data. |
Impact on Developers and Teams
When you use Copilot, you want reliable help. Instead, you often need to review and correct its output. This extra work can slow down your projects. Developers may lose trust in the models if they see too many mistakes or privacy risks. Teams must spend more time checking for errors and making sure sensitive data does not leak. You might also need to train your team to spot and fix these problems, which takes time and resources.
The models can amplify poor data security practices. If your organization does not manage permissions carefully, Copilot can make things worse by exposing more data than you expect. You need to set strict access controls and monitor how the models interact with your business data.
Real-World Consequences
You can see the effects of these flaws in real situations. The US Congress banned its staff from using Copilot because of fears about data breaches. Leaders worried that sensitive government data could leak to unauthorized cloud services. In another case, researchers found a way to use prompt injection and tool exploits to steal personal data through Copilot. These incidents show that the risks are not just theoretical.
If you rely on models that do not protect your data or provide accurate answers, you face real business risks. Sensitive information can leak, and your team may waste time fixing mistakes. You need models that give you both accuracy and privacy to keep your work safe and efficient.
The SLM Revolution in AI

What Are Small Language Models?
You may have heard about the slm revolution, but what does it mean for you? Small language models are a new type of ai that focus on efficiency and accuracy. These models use fewer resources than traditional systems. You can run them on regular computers or even on your own servers. This makes them easy to deploy in your workplace. Small language models help you complete tasks like summarizing emails, extracting key points from meetings, and classifying documents. You get fast answers without waiting for cloud servers. The slm revolution gives you more control over your data and your workflow.
SLMs vs. Large Language Models
You might wonder how small language models compare to large language models. The main difference is size and focus. Large language models need expensive hardware and often run in the cloud. Small language models work on local machines and use less power. You can see the differences in the table below:
| Characteristic | Small Language Models (SLMs) | Large Language Models (LLMs) |
|---|---|---|
| Efficiency | Train and run on commodity hardware | Requires expensive cloud GPUs |
| Deployment | On-premises for enhanced privacy | Often cloud-based |
| Cost-Effectiveness | Lower operational costs | Higher operational costs |
| Performance | Fast inference with a small footprint | Slower due to larger size |
| Hallucination Reduction | Fine-tuned on specific datasets for reliable outputs | More prone to hallucinations |
| Use Cases | Tailored for specific tasks in the SDLC | General-purpose applications |
| Security | Keeps sensitive data in-house | Data may be exposed externally |
You can see that slms offer speed, privacy, and cost savings. You do not need to rely on outside servers. You keep your sensitive information safe.
Why the SLM Revolution Matters
The slm revolution is changing how you use ai at work. You can now deploy models that fit your needs and protect your data. Many organizations choose slms because they support compliance with rules like HIPAA and GDPR. You can process information locally and avoid sending data to the cloud. This helps you meet strict security standards. The slm revolution also boosts productivity. You get real-time answers and can monitor compliance as you work. You do not have to worry about slow responses or high costs. The slm revolution puts you in control of your ai tools and your business data.
Note: The slm revolution is not just about technology. It is about giving you the power to use ai safely, quickly, and efficiently.
How Small Language Models Fix Copilot’s Flaw
Reducing Hallucinations
You want your ai tools to give you reliable answers. Small language models help you achieve this goal. These models focus on accuracy and context. They use targeted training data and optimization techniques to reduce hallucinations. You see fewer invented packages and more trustworthy code suggestions. When you use models like Microsoft’s Phi Family, you get security-first code generation. This means your code stays clean and safe.
Small language models excel in real-time applications. You can use them for intelligent refactoring and automated requirements analysis. They help you optimize your code and avoid mistakes. You notice performance gains because the models deliver effective and fast results. You spend less time correcting errors and more time building solutions.
Enhancing Privacy and Data Control
You care about security and privacy. Small language models give you control over your data. You can deploy these models on your own devices or servers. This on-device capability keeps sensitive information inside your organization. You do not need to send data to external cloud services. You protect your business and meet compliance standards.
With small language models, you manage permissions and access. You decide who can use the models and what data they can see. This approach supports proactive log analysis and automated incident response. You monitor activity and respond quickly to threats. You keep your applications secure and your data private.
Small language models support optimization for security. You can use them for real-time performance monitoring. They help you classify documents and extract action items without exposing confidential information. You gain peace of mind knowing your data stays safe.
Lowering Costs and Resource Needs
You want to optimize your budget and resources. Small language models offer high efficiency and low latency. You can run them on commodity hardware. You do not need expensive cloud GPUs or large infrastructure. This reduces your operational costs and makes ai accessible to more teams.
Look at the cost comparison table below. You see how small language models like Phi-3 Mini save money compared to large models:
| Model | Input Cost ($/M tokens) | Output Cost ($/M tokens) |
|---|---|---|
| GPT-5.5 | $5.00 | $15.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| Gemini 3.1 Pro | $3.50 | $10.50 |
| Mistral 7B (via API) | $0.20 | $0.20 |
| Llama 3.1 8B (via API) | $0.18 | $0.18 |
| Phi-3 Mini (self-hosted) | Hardware cost only | Hardware cost only |
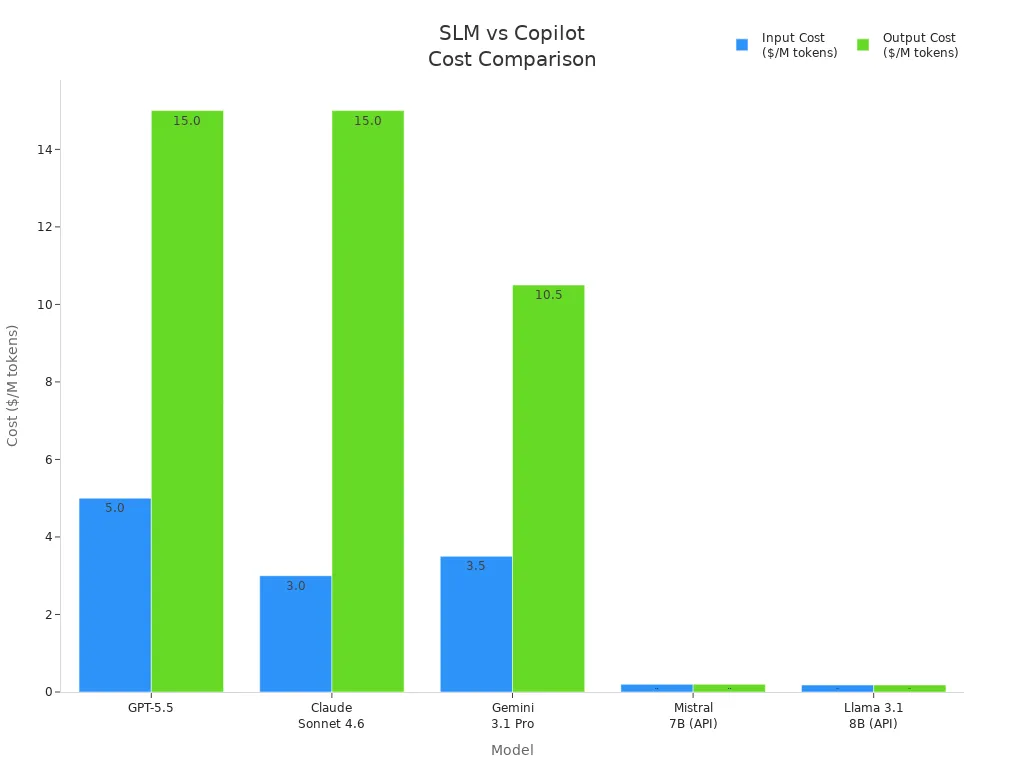
You see that Phi-3 Mini only requires hardware costs. You avoid ongoing token fees. This optimization lets you scale your applications without worrying about rising expenses. You achieve data efficiency and high responsiveness. Your applications run with low latency and real-time performance.
Small language models support optimization for many tasks. You use them for refactoring, code generation, and document classification. You get performance that matches your needs. You can deploy models locally and maintain security. You build applications that deliver value and stay within budget.
Tip: Small language models help you optimize your workflow. You gain speed, privacy, and cost savings. You can focus on building great applications and improving your team’s productivity.
Speed and Responsiveness
You expect your AI tools to respond quickly. Slow answers can disrupt your workflow and waste your time. Small Language Models, like Microsoft’s Phi Family, give you fast results. You see answers in milliseconds, not seconds. This speed helps you stay focused and productive.
You can run SLMs on your own devices or servers. You do not need to wait for cloud processing. Your requests stay local, so you get instant feedback. This is important for mobile workers and teams in the field. You can access information right when you need it.
The Phi Family models use efficient algorithms. They process tasks with minimal delay. You notice the difference when you summarize emails, extract action items, or classify documents. Your team can handle more tasks in less time.
Tip: Fast AI responses mean you spend less time waiting and more time creating value.
Here is a table showing how SLMs compare to large models in response time:
| Model Type | Average Response Time |
|---|---|
| Large Language Model | 2-5 seconds |
| Small Language Model (Phi) | < 0.5 seconds |
You can see that SLMs deliver answers almost instantly. This speed improves your experience and keeps your projects moving.
You also gain reliability. Fast responses mean fewer interruptions. Your applications run smoothly. You can trust your AI tools to keep up with your pace.
Small Language Models help you build responsive apps. You can integrate them into your workflow. Your team benefits from real-time insights and quick decision-making.
Note: Speed and responsiveness are not just technical features. They are key to making AI useful in your daily work.
Enterprise Benefits of SLMs
Cost Savings in Practice
You want to see real savings when you invest in ai tools. Small Language Models deliver impressive cost optimization for enterprises. Many companies have replaced larger models with smaller ones that are 5 to 150 times cheaper. You can achieve better results for specific tasks without paying high fees for cloud processing. The following table shows how leading organizations benefit from SLMs:
| Company | Model Type | Cost Reduction | Performance Comparison |
|---|---|---|---|
| Checkr | 7B-14B parameter | 5-150x less | Better results |
| NVIDIA | 7B-14B parameter | 5-150x less | Better results |
| Bayer | 7B-14B parameter | 5-150x less | Better results |
| DoorDash | 7B-14B parameter | 5-150x less | Better results |
You can reduce your total ai costs by 85-95% compared to traditional large model solutions. This lets you scale your operations and invest in other areas of your business.
Local Deployment and Data Sovereignty
You need to protect your data and meet compliance requirements. SLMs allow you to deploy ai locally, keeping sensitive information inside your organization. Regulated industries like healthcare, finance, and law prefer local setups because they offer strict security and privacy. You avoid sending data to external servers, which reduces the risk of breaches and supports regulatory standards.
- Local deployment ensures zero data transmission to outside servers.
- You can fine-tune models with proprietary data, making ai decisions transparent and compliant.
- Nations and organizations invest in sovereign ai solutions to control their information and strengthen regional resilience.
Hybrid approaches also help you balance local execution for sensitive data with cloud offloading for scalability and accuracy. You gain flexibility while maintaining control.
Productivity Gains in Microsoft 365
You want your team to work faster and smarter. SLMs integrated into Microsoft 365 boost productivity by delivering rapid responses and accurate results. You see inference latency drop to 50-150 milliseconds, compared to 200-1,000 milliseconds for larger models. Your employees get instant answers when summarizing emails, extracting action items, or classifying documents.
- Specialized SLMs achieve 85-97% accuracy in narrow domains, outperforming general models.
- On-device processing keeps your workflow smooth and secure.
- You reduce technical support needs and maintain compliance as you work.
You also help the environment. SLM training produces a much smaller carbon footprint, often between 2-50 tons CO2 equivalent, while large models can exceed 500 tons. You make your business more sustainable and efficient.
Tip: SLMs give you the power to optimize costs, protect your data, and boost productivity—all within your existing Microsoft 365 environment.
Use Cases: Phi Family in Action
You want to see how small language models work in real business situations. The Phi Family gives you practical solutions that help you solve daily challenges. You can use these models to improve communication, boost productivity, and support your team in many ways.
Here are some real-world examples of how you can use the Phi Family in your organization:
Multilingual Customer Support Chatbots
You can build chatbots with Phi-3.5 that answer customer questions in many languages. This helps you serve customers from different countries without hiring extra staff. Your support team becomes more efficient, and your customers get help faster.Multilingual Content Generation
You can automate the creation of marketing content for different regions. Phi-3.5 helps you write ads, emails, and social media posts in several languages. This makes your brand more relatable to people from different cultures. You reach more customers and grow your business.Document Translation and Summarization
You can use Phi-3.5 to translate and summarize long or complex documents. This is useful if you work in law, education, or research. You save time by getting clear summaries and accurate translations. Your team can focus on important tasks instead of manual work.
Tip: You can combine these use cases to create even more value. For example, you can translate customer feedback, summarize it, and use the results to improve your products.
You do not need special hardware or cloud services to use the Phi Family. You can run these models on your own servers or devices. This keeps your data safe and helps you meet privacy rules. You control where your information goes and who can access it.
You also gain speed. The Phi Family gives you answers in milliseconds. Your team does not have to wait for slow cloud responses. This makes your workflow smoother and keeps your projects on track.
You can see that the Phi Family fits many industries. Whether you work in customer service, marketing, law, or education, you find ways to use these models every day. You help your team work smarter and deliver better results.
Note: The Phi Family of Small Language Models gives you the tools to solve real problems. You can start small and scale up as your needs grow.
Trade-Offs and Limitations
Scope and Specialization
Small Language Models (SLMs) give you speed and privacy, but you should know their limits. SLMs focus on specific tasks and domains. They do not cover as much ground as large language models (LLMs). You may notice these differences:
- SLMs have smaller knowledge bases than LLMs.
- They sometimes give vague answers on open-ended or unfamiliar topics.
- SLMs can struggle with long documents or complex reasoning.
- You may see less consistency in long text or when switching between topics.
- SLMs do not generalize as well, so they may not perform as strongly in new or cross-domain tasks.
If you need a model for broad, open-domain questions, SLMs may not always meet your needs. For focused tasks, though, they shine.
Bias and Dataset Size
You want fair and accurate results from your AI. The way SLMs and LLMs handle bias and data size is different. SLMs use smaller, carefully chosen datasets. This helps reduce bias and keeps your data private. LLMs train on huge, open datasets, which can bring in unwanted bias or errors.
Here is a table that shows how SLMs and LLMs compare:
| Aspect | SLMs | LLMs |
|---|---|---|
| Bias Risk | Lower due to smaller, curated datasets | Higher due to training on raw, diverse data |
| Training Data | Domain-specific, curated | Openly accessible, potentially biased data |
| Model Architecture | Less complex, reducing bias risk | More complex, may inadvertently enforce bias |
| Performance in Tasks | Effective in specialized domains | Strong in open-domain tasks but may have factual errors |
LLMs sometimes make factual mistakes or repeat bias from their training data. SLMs, with their focused training, help you avoid these problems and protect your privacy.
Note: SLMs are not perfect, but their smaller, curated datasets make them a safer choice for sensitive or regulated work.
Accessibility and API Availability
You want easy access to AI tools. SLMs give you more options for how you use and deploy them. Many developers find that running SLMs locally makes AI more accessible and affordable. In a study with 180 developers, local deployment of SLMs cut costs by 33% compared to commercial APIs. You can experiment more and learn faster when you control the model on your own hardware.
- Commercial LLM APIs can be expensive and slow, and they may raise privacy concerns.
- Open-source models exist, but you need some technical skill to set them up.
- Local hosting of SLMs lets you manage your data and costs more effectively.
You get more flexibility and control with SLMs. You can choose how to deploy them, who can access them, and how to keep your data safe.
Tip: If you want to experiment, save money, and protect your data, SLMs offer a practical path forward.
Deploying SLMs in the Real World

Deployment Options
You have several ways to deploy Small Language Models in your organization. You can choose the best option based on your needs and resources. Many teams use edge devices for real-time processing. These devices let you run models locally, so you get fast answers and keep your data secure. Cloud deployment gives you scalability and easy management. You can handle large workloads and update models quickly, but you may face latency and depend on internet access.
On-premises deployment keeps your sensitive information inside your company. You control your infrastructure and meet strict compliance rules. Hybrid setups combine local and cloud resources. You balance speed, privacy, and scalability.
Here is a table showing the main deployment options:
| Deployment Option | Advantages | Disadvantages |
|---|---|---|
| Edge Deployment | Real-time processing on devices | Limited computational resources |
| Cloud Deployment | Scalable and efficient management | Potential latency and dependency on internet |
| On-Premises | Full control and compliance | Higher setup and maintenance costs |
| Hybrid | Flexibility and balanced performance | Complexity in integration and management |
When you plan your deployment, you should identify your workload scope, audit data governance, measure computational power, estimate user load, and consider your future roadmap.
Fine-Tuning and Customization
You can fine-tune Small Language Models to fit your business needs. Fine-tuning lets you adjust the model’s behavior and improve accuracy for your tasks. You start by preparing and cleaning your data. You select the best base model for your goals. You connect the model to live databases, so your AI gives up-to-date answers.
You apply security protocols, like masking personal information, to meet global standards. You label your corporate data and train the model to match your brand voice and technical processes. You test the model in real-world scenarios to check for accuracy and bias. You deploy the model and monitor its performance, retraining as needed.
A study showed that a fine-tuned small model can outperform larger models at a fraction of the cost. You can serve many requests cheaply and achieve high quality. Fine-tuning helps you get the same results as bigger models, but with less expense and faster response.
Integration with Developer Workflows
You want your AI tools to fit smoothly into your workflow. You may face challenges like data leakage, complicated prompt engineering, and high resource use. You can solve these problems by using private datasets and robust evaluation protocols. You fine-tune your models to reduce unwanted knowledge and improve decision-making.
You integrate SLMs with your development tools and automate tasks like code generation and document classification. You run models on edge devices for instant feedback and secure processing. You monitor performance and adjust your setup to keep your workflow efficient.
Tip: Start with small tasks and scale up as you gain confidence. You can build reliable, fast, and secure AI solutions that help your team work smarter.
Open-Source vs. Proprietary Models
You face an important choice when you decide to deploy Small Language Models: open-source or proprietary. Each path offers unique advantages and challenges. Understanding these differences helps you make the best decision for your organization.
Open-source SLMs give you freedom and flexibility. You can access the source code, modify it, and adapt the model to your needs. This approach works well if you want to experiment, customize, or control your AI tools. You can run these models on your own hardware, which helps you protect sensitive data and meet compliance requirements. Many developers choose open-source slms because they want transparency and community support.
Proprietary models, on the other hand, come from companies that build and maintain them. You get a polished product with professional support and regular updates. These models often include advanced features, security patches, and integration with other enterprise tools. If you want a solution that works out of the box and comes with a service agreement, proprietary models may fit your needs.
You should consider several factors when making your choice:
- Customization: Open-source models let you fine-tune and adapt the AI for your specific tasks. Proprietary models may limit your ability to change the core system.
- Cost: Open-source models usually have no licensing fees. You only pay for hardware and maintenance. Proprietary models often require subscriptions or usage fees.
- Support: Proprietary models offer dedicated support and documentation. Open-source models rely on community forums and shared resources.
- Security and Compliance: Both options can meet high security standards, but open-source models give you more control over data handling.
A table can help you compare the two options:
| Feature | Open-Source SLMs | Proprietary SLMs |
|---|---|---|
| Customization | High | Moderate to Low |
| Cost | Hardware/maintenance only | Subscription/usage fees |
| Support | Community-driven | Professional, dedicated |
| Updates | Community contributions | Regular, vendor-driven |
| Data Control | Full (local deployment possible) | Varies by vendor |
Recent research from Stanford HAI shows that specialized SLMs reach 85-97% accuracy in narrow domains. This outperforms many general-purpose large models. You benefit from this performance when you tailor models for your business. The economic advantages of SLMs also drive adoption, as you can achieve high-quality results without high costs. Many companies now choose both open-source and proprietary models, focusing on those designed for specific tasks rather than generic solutions.
Tip: Start with your business goals. If you need flexibility and control, open-source SLMs may be the best fit. If you want reliability and support, consider proprietary options. You can also mix both types to get the best of each world.
The Future of Small Language Models
Trends in SLM Development
You see small language models (SLMs) growing fast across many industries. Companies want AI that works well, costs less, and keeps data safe. SLMs now power smart tools in healthcare, finance, and manufacturing. You can check the table below to see how different regions and industries use SLMs:
| Segment | Insights |
|---|---|
| Healthcare | SLMs help with patient engagement and communication through chatbots and assistants. |
| U.S. Market Trends | The U.S. leads in SLM use, with companies like Microsoft pushing new models forward. |
| European Trends | Europe focuses on ethical AI and uses SLMs for customer support and content creation. |
| Asia Pacific Trends | Fast growth as businesses want efficient language tools for many sectors. |
You notice new trends shaping SLMs. Developers use parameter-efficient fine-tuning (PEFT) and knowledge distillation to make models smarter without needing big computers. Quantized models now run on edge devices, so you get fast answers even on small hardware. SLMs support automation and predictive insights in many fields. You benefit from models that fit your needs and work where you need them.
| Trend Type | Description |
|---|---|
| Key Innovation Trends | PEFT and knowledge distillation make SLMs efficient and easy to adapt. |
| Industry Adoption | SLMs drive automation in manufacturing, finance, and cybersecurity. |
| Driver | Demand for fast, low-compute AI pushes SLM adoption. |
| Opportunity | SLMs tailored for healthcare and finance improve precision and compliance. |
| Challenge | Balancing accuracy and efficiency remains a key focus for developers. |
Expanding Capabilities
You may think SLMs only handle simple tasks, but that is changing. Recent research shows SLMs can now take on complex jobs once reserved for large language models. For example, SLMs can process images, text, and even help robots understand their environment. You see SLMs working with larger models to manage tasks like document analysis, vision-language understanding, and real-time decision-making.
| Study | Contribution |
|---|---|
| Collaborative Mechanisms | SLMs handle lower-level tasks in multimodal systems, making AI more efficient. |
| LLM Distillation | SLMs learn from larger models to perform multitask learning in specialized areas. |
| VITA-1.5 Model | SLMs process specific data types before sending information to larger models. |
| Long-Context Vision | SLMs manage visual information for long documents or images. |
| Embodied Agent Systems | SLMs work in robotics, helping machines act in real-world settings. |
| Cloud-Edge Collaboration | SLMs handle specialized tasks in enterprise environments, reducing costs and latency. |
| Enterprise SLM Solution | SLMs now match the performance of larger models for many business tasks. |
You gain more from SLMs as they learn to handle new challenges. These models now support multitasking, work with different types of data, and deliver results quickly.
The Role of Microsoft Phi
You see Microsoft’s Phi Family leading the way in SLM innovation. Experts highlight that Phi models, like Phi-4-mini, work well on edge devices. You can use them in places with weak internet or strict privacy needs. These models help you boost efficiency in manufacturing, healthcare, and retail. Phi-4-mini and Phi-4-multimodal models need less computing power, so you save money and get faster results. Their longer context window lets you analyze large documents or data sets with ease.
"Language models are powerful reasoning engines, and integrating small language models like Phi into Windows allows us to maintain efficient compute capabilities and opens the door to a future of continuous intelligence baked in across all your apps and experiences. Copilot+ PCs will build upon Phi-4-multimodal’s capabilities, delivering the power of Microsoft’s advanced SLMs without the energy drain. This integration will enhance productivity, creativity, and education-focused experiences, becoming a standard part of our developer platform." —Vivek Pradeep, Vice President Distinguished Engineer of Windows Applied Sciences.
You can expect Microsoft Phi to keep driving new uses for SLMs. As these models become part of your daily tools, you will see smarter, faster, and more secure AI everywhere you work.
You see how Small Language Models, like Microsoft’s Phi Family, fix Copilot’s biggest flaw. These models give you:
- High accuracy on specialized tasks with low risk of errors
- Fast processing and low latency for real-time answers
- Strong privacy with on-premises deployment
- Lower costs and less need for expensive hardware
You can automate customer support, classify tickets, and process regulatory documents efficiently. Experts predict AI will soon join the workforce and transform industries. You should consider SLMs for your business and stay ready for the next wave of AI innovation.
FAQ
What is a Small Language Model (SLM)?
A Small Language Model uses fewer parameters than large models. You can run SLMs on local devices. SLMs deliver fast, accurate results for specific tasks like summarizing emails or classifying documents.
How does Microsoft’s Phi Family improve privacy?
You deploy Phi models locally. Your data stays within your organization. You control access and meet compliance requirements. Phi models help you protect sensitive information and reduce privacy risks.
Can I use SLMs without expensive hardware?
Yes! You run SLMs like Phi-3 Mini on regular computers or servers. You avoid costly cloud GPUs. SLMs work efficiently with minimal resources, making AI accessible for your team.
How do SLMs reduce hallucinations in code suggestions?
SLMs use targeted training and optimization. You see fewer invented packages and more reliable answers. Phi models focus on accuracy, helping you trust your AI-generated code.
What tasks can SLMs handle in Microsoft 365?
You use SLMs to summarize emails, extract action items, classify documents, and automate routine tasks. SLMs boost productivity and deliver quick, accurate results in your daily workflow.
Are SLMs suitable for regulated industries?
Yes. You deploy SLMs locally to keep data secure. Healthcare, finance, and legal teams use SLMs to meet strict privacy and compliance standards. You maintain control over sensitive information.
How do SLMs help reduce AI costs?
SLMs require only hardware costs for self-hosted deployment. You avoid ongoing token fees. You scale your AI solutions affordably and achieve significant savings compared to large models.
🚀 Want to be part of m365.fm?
Then stop just listening… and start showing up.
👉 Connect with me on LinkedIn and let’s make something happen:
- 🎙️ Be a podcast guest and share your story
- 🎧 Host your own episode (yes, seriously)
- 💡 Pitch topics the community actually wants to hear
- 🌍 Build your personal brand in the Microsoft 365 space
This isn’t just a podcast — it’s a platform for people who take action.
🔥 Most people wait. The best ones don’t.
👉 Connect with me on LinkedIn and send me a message:
"I want in"
Let’s build something awesome 👊
1
00:00:00,000 --> 00:00:03,200
You probably think co-pilot's biggest flaw is the license price.
2
00:00:03,200 --> 00:00:06,500
But in reality, the license is the smallest part of the problem.
3
00:00:06,500 --> 00:00:09,700
The real issue is what's behind every co-pilot request.
4
00:00:09,700 --> 00:00:12,800
A frontier model that costs too much responds to slowly
5
00:00:12,800 --> 00:00:16,000
and processes your data in jurisdictions you don't control.
6
00:00:16,000 --> 00:00:19,500
There's a better architecture and it starts with thinking smaller.
7
00:00:19,500 --> 00:00:20,900
The broken assumption.
8
00:00:20,900 --> 00:00:22,000
Bigger is better.
9
00:00:22,000 --> 00:00:25,400
Your organization didn't set out to over-engineer its AI strategy.
10
00:00:25,400 --> 00:00:28,000
You wanted co-pilot because it promised to make your teams faster,
11
00:00:28,000 --> 00:00:30,400
your decisions sharper and your workflows smarter.
12
00:00:30,400 --> 00:00:32,500
So you bought the licenses, enabled the features,
13
00:00:32,500 --> 00:00:36,500
and started routing every request through the most capable model Microsoft offered.
14
00:00:36,500 --> 00:00:40,200
That felt like the right move because in 2023, bigger really was better.
15
00:00:40,200 --> 00:00:43,000
GPT-4 could do things that smaller models couldn't touch
16
00:00:43,000 --> 00:00:46,800
and the gap was so wide that choosing anything else felt like settling.
17
00:00:46,800 --> 00:00:49,800
But in reality, that assumption has become a structural flaw.
18
00:00:49,800 --> 00:00:55,000
Enterprise AI in 2026 isn't a research lab where every task demands frontier level reasoning.
19
00:00:55,000 --> 00:01:00,300
It's a production environment where thousands of employees are doing the same narrow tasks repeatedly.
20
00:01:00,300 --> 00:01:03,600
They are summarizing email threads, they're extracting action items from meetings,
21
00:01:03,600 --> 00:01:07,600
they are classifying documents, drafting replies, and searching through SharePoint.
22
00:01:07,600 --> 00:01:12,200
These tasks don't need a trillion parameter model that can write poetry and debug code.
23
00:01:12,200 --> 00:01:15,600
They need a model that can do the specific job quickly, cheaply,
24
00:01:15,600 --> 00:01:19,000
and without sending your data on a round trip through a data center, you don't own.
25
00:01:19,000 --> 00:01:23,300
The research points to a clear shift in how Microsoft itself is architecting co-pilot.
26
00:01:23,300 --> 00:01:26,900
The company reorganized its co-pilot division in March 2026,
27
00:01:26,900 --> 00:01:30,400
moving consumer and commercial co-pilot under a single organization
28
00:01:30,400 --> 00:01:32,400
with a mandate to build tiered capabilities.
29
00:01:32,400 --> 00:01:37,400
The memo from Satya Nadella explicitly tied model development to product benchmarks and serving costs.
30
00:01:37,400 --> 00:01:40,400
Microsoft isn't betting on one massive model anymore.
31
00:01:40,400 --> 00:01:44,400
It's building a portfolio where different model sizes serve different tiers of user need.
32
00:01:44,400 --> 00:01:45,600
That should tell you something.
33
00:01:45,600 --> 00:01:48,600
The company that built co-pilot around open AI's largest models
34
00:01:48,600 --> 00:01:51,100
is now actively working to reduce its dependence on them.
35
00:01:51,100 --> 00:01:55,200
Not because the big models are bad, but because using them for everything is architecturally wrong.
36
00:01:55,200 --> 00:01:57,400
It's like deploying a mainframe to run a spreadsheet.
37
00:01:57,400 --> 00:02:00,900
The compute is real and the capability is undeniable, but the fit is broken.
38
00:02:00,900 --> 00:02:03,900
And the cost of that broken fit isn't just theoretical.
39
00:02:03,900 --> 00:02:07,400
It shows up in three places that every IT leader and architect can measure.
40
00:02:07,400 --> 00:02:10,400
The first is money, the second is time, and the third is control.
41
00:02:10,400 --> 00:02:12,700
Let's talk about what each one is actually costing you.
42
00:02:12,700 --> 00:02:15,700
The cognitive dissonance here is worth naming explicitly.
43
00:02:15,700 --> 00:02:18,300
Most organizations know their AI spending is growing.
44
00:02:18,300 --> 00:02:19,600
They see the monthly Azure Bill.
45
00:02:19,600 --> 00:02:24,500
They track the co-pilot license costs, but they don't connect the individual click to the cumulative meter.
46
00:02:24,500 --> 00:02:29,400
An employee in Outlook hits, summarizes thread, without thinking about the tokens.
47
00:02:29,400 --> 00:02:33,600
A manager in Teams asks for a meeting recap without considering the inference cost.
48
00:02:33,600 --> 00:02:38,600
A finance analyst requests a formula explanation without realizing it just triggered a premium model call.
49
00:02:38,600 --> 00:02:42,200
These micro decisions repeated thousands of times across hundreds of users,
50
00:02:42,200 --> 00:02:45,200
aggregate into macro spending that no one budgeted for.
51
00:02:45,200 --> 00:02:48,500
And because the spending is metered rather than fixed, it's unpredictable.
52
00:02:48,500 --> 00:02:51,800
Your co-pilot usage in March might be W usage in February,
53
00:02:51,800 --> 00:02:55,100
because of a product launch, a compliance deadline, or a seasonal peak.
54
00:02:55,100 --> 00:02:57,100
The finance team can't forecast it.
55
00:02:57,100 --> 00:02:59,100
The procurement team can't negotiate it.
56
00:02:59,100 --> 00:03:02,200
And the IT team finds itself in the uncomfortable position of explaining
57
00:03:02,200 --> 00:03:06,100
why a $30 per user license turned into a six-figure annual variable cost
58
00:03:06,100 --> 00:03:07,900
that wasn't on anyone's roadmap.
59
00:03:07,900 --> 00:03:09,400
This is the structural flaw in action.
60
00:03:09,400 --> 00:03:13,300
It is not a bug in co-pilot, and it is not a pricing trick by Microsoft.
61
00:03:13,300 --> 00:03:16,500
Just an architectural mismatch between a general purpose supermodel
62
00:03:16,500 --> 00:03:18,700
and a narrow-purpose production workload.
63
00:03:18,700 --> 00:03:23,800
And that mismatch is what small-language models are specifically engineered to solve.
64
00:03:23,800 --> 00:03:26,300
The cost reality, the co-pilot text.
65
00:03:26,300 --> 00:03:30,400
Most organizations think about co-pilot cost as a per-seed license.
66
00:03:30,400 --> 00:03:33,800
You pay $30 per user per month, and that's your AI budget.
67
00:03:33,800 --> 00:03:36,000
But in reality, that's only the entry fee.
68
00:03:36,000 --> 00:03:40,800
The real cost is what happens every time one of your employees clicks the co-pilot button.
69
00:03:40,800 --> 00:03:43,000
Every request hits a large language model.
70
00:03:43,000 --> 00:03:45,100
Every token of input and output is metered.
71
00:03:45,100 --> 00:03:48,800
And when you're running a frontier model like GPT-40 at enterprise scale,
72
00:03:48,800 --> 00:03:51,800
those tokens add up faster than most finance teams realize.
73
00:03:51,800 --> 00:03:58,600
Research on enterprise AI workloads shows that GPT-40 runs at roughly $4 to $5 per million tokens on a blended basis.
74
00:03:58,600 --> 00:04:01,600
That sounds small until you multiply it by thousands of users,
75
00:04:01,600 --> 00:04:03,700
making dozens of requests every single day.
76
00:04:03,700 --> 00:04:07,900
A single team of 50 people each using co-pilot for routine drafting and summarization
77
00:04:07,900 --> 00:04:11,100
can burn through millions of tokens in a month without anyone noticing.
78
00:04:11,100 --> 00:04:13,200
Now compare that to small-language models.
79
00:04:13,200 --> 00:04:18,700
5.3.5 mini, one of Microsoft's own SLMs, runs at about $0.10 per million tokens.
80
00:04:18,700 --> 00:04:19,900
That's not a minor discount.
81
00:04:19,900 --> 00:04:24,200
That's a 300 times difference on input costs and a 600 times difference on output.
82
00:04:24,200 --> 00:04:29,500
For high volume, low complexity tasks, the exact tasks that make up 80% of daily co-pilot usage,
83
00:04:29,500 --> 00:04:32,600
that gap turns a manageable line item into a budget crisis.
84
00:04:32,600 --> 00:04:36,100
The research on enterprise cost analysis puts this in stock terms.
85
00:04:36,100 --> 00:04:41,300
Organizations running hybrid architectures where SLMs handle routine traffic and frontier models
86
00:04:41,300 --> 00:04:46,200
stay in reserve for complex cases, are seeing 5 to 7 times annual cost reductions
87
00:04:46,200 --> 00:04:48,600
compared to LLM first designs.
88
00:04:48,600 --> 00:04:52,700
Some specific workloads report per inference savings of 10 to 100 times.
89
00:04:52,700 --> 00:04:57,300
And when you self-host an SLM on your own infrastructure, the economics get even sharper.
90
00:04:57,300 --> 00:05:01,700
The break-even period for on-premise small models is measured in months, not years.
91
00:05:01,700 --> 00:05:04,500
Here's why this matters for your co-pilot strategy specifically.
92
00:05:04,500 --> 00:05:06,800
Microsoft 365 co-pilot isn't one feature.
93
00:05:06,800 --> 00:05:12,100
It's dozens of features embedded across outlook, teams, word, Excel and SharePoint.
94
00:05:12,100 --> 00:05:16,600
Every summarized email thread is a request, every meeting recap is a request, every draft reply,
95
00:05:16,600 --> 00:05:19,800
every document query, every data extraction, they're all requests.
96
00:05:19,800 --> 00:05:24,700
If every single one of them hits a frontier model, you're paying premium prices for basic tasks.
97
00:05:24,700 --> 00:05:27,600
The smart enterprises aren't debating whether to keep co-pilot.
98
00:05:27,600 --> 00:05:30,300
They're debating which model should power each part of it.
99
00:05:30,300 --> 00:05:35,000
And the answer for the bulk of daily work is not the biggest one, consider what this means at scale.
100
00:05:35,000 --> 00:05:41,000
A mid-sized enterprise with 2,000 co-pilot users might generate 20 million tokens per month on routine tasks alone.
101
00:05:41,000 --> 00:05:46,800
A GPT-40 blended rates that's 80 to $100,000 in inference costs annually on top of license fees.
102
00:05:46,800 --> 00:05:49,800
At 5, 3.5 mini-rates, it's $2,000.
103
00:05:49,800 --> 00:05:50,800
The difference.
104
00:05:50,800 --> 00:05:58,000
$78 to $98,000 per year for a single mid-sized deployment is more than enough to fund a dedicated AI infrastructure engineer,
105
00:05:58,000 --> 00:06:02,800
a local GPU server and the operational tooling to manage a hybrid architecture.
106
00:06:02,800 --> 00:06:06,600
And that's before you factor in the latency improvements, the sovereignty benefits,
107
00:06:06,600 --> 00:06:10,800
and the user adoption gains that come with faster, more responsive tools.
108
00:06:10,800 --> 00:06:15,400
The research on enterprise cost analysis puts the break-even math in even sharper terms.
109
00:06:15,400 --> 00:06:23,400
Organizations processing at least 50 million tokens per month see break-even periods for on-premise small models measured in months rather than years.
110
00:06:23,400 --> 00:06:29,800
At that volume, the capital expenditure of a local server pays for itself in under two quarters compared to cloud API consumption.
111
00:06:29,800 --> 00:06:33,800
For organizations already operating Azure local or on-premise Kubernetes clusters,
112
00:06:33,800 --> 00:06:39,200
the incremental cost of adding an SLM workload is often just the GPU allocation and the operator time.
113
00:06:39,200 --> 00:06:41,000
The infrastructure is already there.
114
00:06:41,000 --> 00:06:43,800
This is why the per-seat license framing is so misleading.
115
00:06:43,800 --> 00:06:47,600
It treats co-pilot as a fixed-cost software product, like office or teams.
116
00:06:47,600 --> 00:06:52,200
But the AI layer underneath is a variable cost utility like electricity or bandwidth.
117
00:06:52,200 --> 00:06:56,800
And just as smart organizations negotiate bandwidth contracts and optimize compute utilization,
118
00:06:56,800 --> 00:07:00,200
smart organizations now need to optimize their model utilization.
119
00:07:00,200 --> 00:07:01,400
The license gets you access.
120
00:07:01,400 --> 00:07:04,400
The model selection determines what that access actually costs.
121
00:07:04,400 --> 00:07:09,400
The latency problem waiting for intelligence cost hurts your budget latency hurts your users.
122
00:07:09,400 --> 00:07:14,800
And when users stop trusting a tool because it's too slow, the ROI collapses regardless of what you paid for it.
123
00:07:14,800 --> 00:07:17,800
A cloud hosted frontier model doesn't just cost more per token.
124
00:07:17,800 --> 00:07:19,400
It takes longer to respond.
125
00:07:19,400 --> 00:07:28,000
Research on Azure AI task latency shows that GPT-4 class models typically deliver first token latency in the range of 300 to 2000 milliseconds,
126
00:07:28,000 --> 00:07:30,600
depending on load, region and context length.
127
00:07:30,600 --> 00:07:33,400
That's before the model even starts generating useful output.
128
00:07:33,400 --> 00:07:35,600
Then you wait for the full response to stream back.
129
00:07:35,600 --> 00:07:39,400
For a user writing a quick email draft, two seconds feels like an eternity.
130
00:07:39,400 --> 00:07:42,800
For a team's meeting that needs real-time summarization, it's unusable.
131
00:07:42,800 --> 00:07:45,800
And for workflows that require multiple model calls and sequence,
132
00:07:45,800 --> 00:07:52,400
classify this document, extract these fields, draft the summary, root it to the right person, the delays multiply.
133
00:07:52,400 --> 00:07:56,200
What looks like a small per request lag becomes a systemic productivity drain.
134
00:07:56,200 --> 00:07:59,000
Small language models change this equation completely.
135
00:07:59,000 --> 00:08:01,600
When deployed on edge hardware or local infrastructure,
136
00:08:01,600 --> 00:08:06,200
SLMs like Phi 3 Mini can deliver first responses in 10 to 50 milliseconds.
137
00:08:06,200 --> 00:08:09,400
On a modest GPU, they generate over 12 tokens per second.
138
00:08:09,400 --> 00:08:13,600
On a phone or laptop, quantized versions still run fast enough to feel instant.
139
00:08:13,600 --> 00:08:15,800
The research makes the comparison explicit.
140
00:08:15,800 --> 00:08:19,400
SLMs respond in 10 to 50 milliseconds on edge deployments.
141
00:08:19,400 --> 00:08:23,600
While cloud LLMs take 300 to 2000 milliseconds for first token latency,
142
00:08:23,600 --> 00:08:25,400
that gap isn't a minor optimization.
143
00:08:25,400 --> 00:08:29,400
It's the difference between a tool that feels like part of your workflow and a tool
144
00:08:29,400 --> 00:08:31,000
that feels like a bottleneck.
145
00:08:31,000 --> 00:08:35,200
Microsoft's own documentation frames this as a core reason to adopt SLMs.
146
00:08:35,200 --> 00:08:39,000
They describe small models as essential for scenarios where limited computing power,
147
00:08:39,000 --> 00:08:41,600
low latency or keeping costs down is critical.
148
00:08:41,600 --> 00:08:45,400
The company isn't positioning SLMs as a budget alternative for small businesses.
149
00:08:45,400 --> 00:08:49,600
It's positioning them as the right architecture for high frequency enterprise tasks.
150
00:08:49,600 --> 00:08:51,800
And here's the part most organizations miss.
151
00:08:51,800 --> 00:08:53,800
Latency isn't just a user experience problem.
152
00:08:53,800 --> 00:08:55,000
It's an adoption problem.
153
00:08:55,000 --> 00:08:58,000
If your employees try co-pilot twice, wait two seconds each time
154
00:08:58,000 --> 00:09:01,200
and decide it's faster to just do the work themselves, they won't come back.
155
00:09:01,200 --> 00:09:05,000
The license is paid and the feature is enabled, but the behavior doesn't stick.
156
00:09:05,000 --> 00:09:07,800
And the ROI you promised your board never materializes.
157
00:09:07,800 --> 00:09:10,800
The psychology of tool adoption follows a predictable curve.
158
00:09:10,800 --> 00:09:14,600
They're really adopters tolerate friction because they're motivated by novelty and status.
159
00:09:14,600 --> 00:09:20,000
They'll wait three seconds for a meeting summary because they want to be the person who uses AI at work.
160
00:09:20,000 --> 00:09:24,600
But the broader employee base, the people who actually determine whether a deployment succeeds or fails,
161
00:09:24,600 --> 00:09:26,000
has a much shorter tolerance.
162
00:09:26,000 --> 00:09:29,200
If the tool doesn't save them time immediately, they abandon it.
163
00:09:29,200 --> 00:09:34,400
And once abandonment becomes the norm, the tool dies by disuse even though the monthly invoice keeps arriving.
164
00:09:34,400 --> 00:09:38,000
Microsoft's own research into co-pilot adoption patterns confirms this.
165
00:09:38,000 --> 00:09:41,200
Most successful deployments aren't the ones with the most features enabled.
166
00:09:41,200 --> 00:09:45,600
The other ones were users formed habits around a small set of high value low friction tasks.
167
00:09:45,600 --> 00:09:50,400
Email summarization that happens instantly, draft replies that appear while they're still reading the thread.
168
00:09:50,400 --> 00:09:53,400
Meeting recaps that are ready before they leave the conference room.
169
00:09:53,400 --> 00:09:56,400
These moments create the behavioral loop that sustains adoption
170
00:09:56,400 --> 00:10:02,400
and these moments are exactly where SLMs excel because their speed makes the interaction feel seamless rather than burdensome.
171
00:10:02,400 --> 00:10:06,000
The contrast becomes even more stark when you consider mobile and field workers.
172
00:10:06,000 --> 00:10:12,400
A sales representative checking a customer account on a tablet between meetings doesn't have the patience for a two-second cloud-round trip.
173
00:10:12,400 --> 00:10:18,600
A warehouse supervisor asking for inventory analysis on a handheld device needs the answer before the next truck arrives.
174
00:10:18,600 --> 00:10:22,600
A field technician troubleshooting equipment in a basement with spotty cellular coverage
175
00:10:22,600 --> 00:10:24,600
can't depend on cloud inference at all.
176
00:10:24,600 --> 00:10:28,200
For these users, local SLM deployment isn't an optimization.
177
00:10:28,200 --> 00:10:31,200
It's the difference between a tool that works and a tool that doesn't.
178
00:10:31,200 --> 00:10:32,200
Then there's the third problem.
179
00:10:32,200 --> 00:10:37,200
The one that doesn't show up in usage metrics or cost reports until it's already a crisis.
180
00:10:37,200 --> 00:10:38,400
The sovereignty gap.
181
00:10:38,400 --> 00:10:40,200
Where your data actually goes.
182
00:10:40,200 --> 00:10:44,400
You probably assume that when your employee asks co-pilot to summarize a contract in word,
183
00:10:44,400 --> 00:10:46,000
the document stays in your tenant.
184
00:10:46,000 --> 00:10:48,600
The processing happens in Microsoft's cloud sure,
185
00:10:48,600 --> 00:10:51,800
but within your EU data center under your compliance regime,
186
00:10:51,800 --> 00:10:53,000
governed by your controls.
187
00:10:53,000 --> 00:10:57,800
That's the enterprise data protection promise, but in reality, it's more complicated than that.
188
00:10:57,800 --> 00:11:01,600
In 2026, Microsoft introduced something called co-pilot flex routing.
189
00:11:01,600 --> 00:11:05,800
It's a feature that allows LLM inferencing to be processed outside the EU
190
00:11:05,800 --> 00:11:08,200
when regional capacity is constrained for new tenants.
191
00:11:08,200 --> 00:11:10,800
It's been enabled by default since March 2026.
192
00:11:10,800 --> 00:11:15,600
And as of April 2026, Microsoft turned it on by default for all EU and EFTI tenants,
193
00:11:15,600 --> 00:11:18,200
unless administrators explicitly disabled it.
194
00:11:18,200 --> 00:11:22,200
When flex routing activates, your co-pilot requests can be processed in data centers
195
00:11:22,200 --> 00:11:24,800
in the United States, Canada, or Australia.
196
00:11:24,800 --> 00:11:27,800
Microsoft states that customer data address remains in the EU
197
00:11:27,800 --> 00:11:29,800
and that data is encrypted in transit.
198
00:11:29,800 --> 00:11:34,600
But the processing itself, the actual inference where your document content is fed into the model
199
00:11:34,600 --> 00:11:36,200
happens outside your jurisdiction.
200
00:11:36,200 --> 00:11:39,200
If you're in a regulated industry, that distinction matters.
201
00:11:39,200 --> 00:11:42,800
Your data protection officer didn't sign off on EU data sitting in EU storage
202
00:11:42,800 --> 00:11:44,800
while being processed in a US facility.
203
00:11:44,800 --> 00:11:47,400
The legal basis for that transfer isn't automatic.
204
00:11:47,400 --> 00:11:50,400
It requires updated records of processing activities,
205
00:11:50,400 --> 00:11:53,600
transfer impact assessments, and a documented risk decision.
206
00:11:53,600 --> 00:11:57,400
And if your national regulator takes the view that processing equals data transfer,
207
00:11:57,400 --> 00:11:59,600
you're in breach, but flex routing isn't the only gap.
208
00:11:59,600 --> 00:12:02,600
Some co-pilot capabilities now call Anthropics Claude models.
209
00:12:02,600 --> 00:12:06,400
Those models are hosted on AWS infrastructure in the United States.
210
00:12:06,400 --> 00:12:10,800
When they're used, your data leaves the EU regardless of your flex routing settings.
211
00:12:10,800 --> 00:12:13,600
Microsoft's enterprise data protection still apply.
212
00:12:13,600 --> 00:12:16,200
No training on your data, encryption in transit,
213
00:12:16,200 --> 00:12:18,400
but the processing location is non-negotiable.
214
00:12:18,400 --> 00:12:21,800
Anthropic models are turned off by default for EU organizations,
215
00:12:21,800 --> 00:12:23,400
but admins can enable them.
216
00:12:23,400 --> 00:12:24,400
And some features do.
217
00:12:24,400 --> 00:12:27,400
Then there's Bing-connected web search inside co-pilot.
218
00:12:27,400 --> 00:12:31,200
Those queries root through services outside your tenant, typically US hosted.
219
00:12:31,200 --> 00:12:35,000
Microsoft says search queries aren't stored or used to profile your tenant,
220
00:12:35,000 --> 00:12:38,200
but for organizations under strict data minimization rules,
221
00:12:38,200 --> 00:12:40,200
trust us isn't a compliance strategy.
222
00:12:40,200 --> 00:12:42,400
The EU data boundary was supposed to solve this.
223
00:12:42,400 --> 00:12:46,200
Microsoft committed that personal data for EU customers would be stored and processed
224
00:12:46,200 --> 00:12:49,200
within the EU or EFTA with limited exceptions.
225
00:12:49,200 --> 00:12:53,400
And the company is rolling out in-country inferencing for co-pilot in 15 countries
226
00:12:53,400 --> 00:12:57,200
by the end of 2026, including regional inferencing for the EU.
227
00:12:57,200 --> 00:12:59,400
But flex routing remains an available switch.
228
00:12:59,400 --> 00:13:01,000
Anthropic remains an optional model.
229
00:13:01,000 --> 00:13:04,200
And the boundary between compliant processing and cross-border inference
230
00:13:04,200 --> 00:13:08,400
is now a configuration checkbox that your admin either disabled or didn't know existed.
231
00:13:08,400 --> 00:13:10,000
This is what I mean by the sovereignty gap.
232
00:13:10,000 --> 00:13:11,800
You bought co-pilot for productivity.
233
00:13:11,800 --> 00:13:16,000
You got a compliance surface area that expands every time Microsoft adds a new model
234
00:13:16,000 --> 00:13:17,200
or a new routing option.
235
00:13:17,200 --> 00:13:20,800
And the default settings are increasingly permissive, not restrictive.
236
00:13:20,800 --> 00:13:24,000
The complexity deepens when you look at the full configuration matrix
237
00:13:24,000 --> 00:13:26,000
that an administrator needs to manage.
238
00:13:26,000 --> 00:13:29,600
Flex routing on or off and through pick models allowed or blocked.
239
00:13:29,600 --> 00:13:32,800
Bingweb search integration enabled or disabled tenant level settings
240
00:13:32,800 --> 00:13:34,800
versus workloads specific settings.
241
00:13:34,800 --> 00:13:37,400
User group policies versus department level exceptions.
242
00:13:37,400 --> 00:13:39,800
Each toggle represents a compliance decision
243
00:13:39,800 --> 00:13:42,800
that your data protection officer probably wasn't consulted on.
244
00:13:42,800 --> 00:13:45,800
And each toggle's default setting, as of 2026,
245
00:13:45,800 --> 00:13:48,400
leans toward functionality rather than restriction.
246
00:13:48,400 --> 00:13:52,400
For organizations in sectors like healthcare, finance, defense, and critical infrastructure,
247
00:13:52,400 --> 00:13:54,600
this isn't a minor administrative inconvenience.
248
00:13:54,600 --> 00:13:56,800
It's a potential breach of statutory obligation.
249
00:13:56,800 --> 00:14:00,600
National data localization laws may explicitly prohibit processing of citizen data
250
00:14:00,600 --> 00:14:04,400
outside national borders, regardless of encryption or contractual safeguards.
251
00:14:04,400 --> 00:14:08,800
Sexual regulators like the European banking authority or national health privacy bodies
252
00:14:08,800 --> 00:14:12,400
may interpret inference processing as a reportable international transfer.
253
00:14:12,400 --> 00:14:15,600
And the Shrem's two decision and its subsequent enforcement actions have made
254
00:14:15,600 --> 00:14:20,200
European data protection authorities increasingly skeptical of standard contractual clauses
255
00:14:20,200 --> 00:14:23,200
as a blanket justification for US linked processing.
256
00:14:23,200 --> 00:14:26,800
The Microsoft EU data boundary is a genuine and substantial investment.
257
00:14:26,800 --> 00:14:30,200
The company has built regional data centers, implemented encryption
258
00:14:30,200 --> 00:14:34,000
and published detailed documentation about what stays in the EU and what doesn't.
259
00:14:34,000 --> 00:14:35,600
But the boundary is not a force field.
260
00:14:35,600 --> 00:14:39,200
It's a configuration and configurations can be changed by product updates,
261
00:14:39,200 --> 00:14:43,000
capacity constraints, or new feature rollouts that your organization
262
00:14:43,000 --> 00:14:45,600
didn't anticipate when it first signed the agreement.
263
00:14:45,600 --> 00:14:50,200
This is why the sovereignty conversation can't end with Microsoft says it's compliant.
264
00:14:50,200 --> 00:14:54,000
It has to extend to can we verify and enforce compliance ourselves.
265
00:14:54,000 --> 00:14:57,200
And that requirement pushes the architecture toward local deployment
266
00:14:57,200 --> 00:15:01,600
where the data doesn't leave your facility because the model is running inside your facility.
267
00:15:01,600 --> 00:15:04,200
No flex-rooting toggle matters when there is no root,
268
00:15:04,200 --> 00:15:07,400
no anthropic model location matters when you're not calling anthropic.
269
00:15:07,400 --> 00:15:12,600
No Bing web search leakage matters when the search layer is disabled or replaced with local retrieval.
270
00:15:12,600 --> 00:15:15,600
The sovereignty gap is the hardest of the three floors to measure
271
00:15:15,600 --> 00:15:17,200
because its cost isn't a line item.
272
00:15:17,200 --> 00:15:21,800
It's a risk. It's the risk of a regulatory find that could reach 4% of global revenue under GDPR.
273
00:15:21,800 --> 00:15:25,600
It's the risk of losing a government contract because your AI processing
274
00:15:25,600 --> 00:15:27,400
can't meet national security requirements.
275
00:15:27,400 --> 00:15:30,200
It's the risk of a reputational crisis when a journalist discovers
276
00:15:30,200 --> 00:15:35,000
that your EU customer data was processed in a US data center during a capacity peak.
277
00:15:35,000 --> 00:15:37,400
These are existential risks for some organizations.
278
00:15:37,400 --> 00:15:40,000
And they're entirely avoidable with the right architecture.
279
00:15:40,000 --> 00:15:41,000
So that's the floor.
280
00:15:41,000 --> 00:15:44,600
Costs that scales unpredictably because every task hits a premium model.
281
00:15:44,600 --> 00:15:47,400
Latency that erodes adoption because users won't wait.
282
00:15:47,400 --> 00:15:49,400
And sovereignty that depends on admin toggles,
283
00:15:49,400 --> 00:15:52,000
most organizations haven't reviewed since deployment.
284
00:15:52,000 --> 00:15:54,600
The fix isn't a bigger license or more cloud capacity.
285
00:15:54,600 --> 00:15:58,800
It's a different model architecture entirely and that's where small language models come in.
286
00:15:58,800 --> 00:16:00,400
What is an SLM really?
287
00:16:00,400 --> 00:16:02,800
Small language models are exactly what the name suggests.
288
00:16:02,800 --> 00:16:06,000
They're language models with fewer parameters and simpler architectures
289
00:16:06,000 --> 00:16:08,200
than the frontier models that dominate the headlines.
290
00:16:08,200 --> 00:16:12,400
Where GPT-4 and its competitors operate at scales measured in hundreds of billions
291
00:16:12,400 --> 00:16:14,000
or even trillions of parameters.
292
00:16:14,000 --> 00:16:18,400
SLMs typically range from roughly 100 million to 7 billion parameters.
293
00:16:18,400 --> 00:16:20,800
That size difference isn't just a technical detail.
294
00:16:20,800 --> 00:16:23,800
It determines where the model can run, how fast it responds,
295
00:16:23,800 --> 00:16:27,200
what it costs to operate and who controls the hardware it runs on.
296
00:16:27,200 --> 00:16:31,000
Microsoft defines SLMs as models built for efficiency and low resource use.
297
00:16:31,000 --> 00:16:34,600
They perform many of the same natural language tasks as their larger cousins.
298
00:16:34,600 --> 00:16:39,200
Summarization, classification, drafting, extraction, translation,
299
00:16:39,200 --> 00:16:43,000
but they're optimized for scenarios where speed, cost, or deployment flexibility
300
00:16:43,000 --> 00:16:45,400
matters more than broad general knowledge.
301
00:16:45,400 --> 00:16:49,800
A 3 billion parameter model doesn't know as much trivia as a 1 trillion parameter model.
302
00:16:49,800 --> 00:16:53,000
But if your task is extracting action items from a team's transcript,
303
00:16:53,000 --> 00:16:56,200
the model doesn't need to know who won the World Cup in 1986.
304
00:16:56,200 --> 00:17:00,800
It needs to understand meeting structure, identify tasks, assign owners and format the output.
305
00:17:00,800 --> 00:17:04,000
That's a narrow job and narrow jobs are what SLMs are built for.
306
00:17:04,000 --> 00:17:07,200
The architectural difference goes deeper than parameter count.
307
00:17:07,200 --> 00:17:09,400
Frontier models are designed to be generalists.
308
00:17:09,400 --> 00:17:13,800
They're trained on enormous, diverse data sets so they can handle almost any prompt you throw at them.
309
00:17:13,800 --> 00:17:16,000
That generality is their superpower and their weakness.
310
00:17:16,000 --> 00:17:18,800
It means they carry enormous amounts of knowledge you'll never use.
311
00:17:18,800 --> 00:17:22,400
It means they require multi-GPU clusters to serve at reasonable speed.
312
00:17:22,400 --> 00:17:25,800
And it means every request, no matter how simple, activates the full model.
313
00:17:25,800 --> 00:17:27,400
SLMs take a different approach.
314
00:17:27,400 --> 00:17:30,600
They're smaller, which means they can run on a single GPU, a modest server,
315
00:17:30,600 --> 00:17:31,800
or even a modern laptop.
316
00:17:31,800 --> 00:17:34,600
They can be fine-tuned quickly on domain-specific data
317
00:17:34,600 --> 00:17:38,400
because training a 3 billion parameter model is vastly cheaper and faster
318
00:17:38,400 --> 00:17:40,600
than training a 100 billion parameter model.
319
00:17:40,600 --> 00:17:43,000
And their narrow focus means they're often more predictable.
320
00:17:43,000 --> 00:17:45,800
They hallucinate less on tasks they've been trained for
321
00:17:45,800 --> 00:17:50,400
because there's less extraneous knowledge competing with the specific patterns they need to recognize.
322
00:17:50,400 --> 00:17:53,400
This is the fundamental reframe that most enterprise teams miss.
323
00:17:53,400 --> 00:17:57,400
They evaluate SLMs by asking whether a small model can do everything a large model can do.
324
00:17:57,400 --> 00:17:58,400
That's the wrong question.
325
00:17:58,400 --> 00:18:02,600
The right question is whether a small model can do the specific tasks you actually need
326
00:18:02,600 --> 00:18:05,800
and whether it can do them faster, cheaper and closer to your data.
327
00:18:05,800 --> 00:18:09,000
The research on SLM architecture makes this distinction explicit.
328
00:18:09,000 --> 00:18:14,000
Small models are particularly effective when fine-tuned for specific narrow domains or tasks.
329
00:18:14,000 --> 00:18:17,600
They offer lower cost, faster response and reduced energy consumption.
330
00:18:17,600 --> 00:18:20,800
And they can run on edge devices or constrained compute environments
331
00:18:20,800 --> 00:18:24,600
where a frontier model simply wouldn't fit Microsoft's own documentation positions
332
00:18:24,600 --> 00:18:28,800
SLMs as the practical alternative, where efficiency and device local deployment matter.
333
00:18:28,800 --> 00:18:30,800
For Microsoft 365 environments,
334
00:18:30,800 --> 00:18:34,200
this capability profile maps almost perfectly to the daily workstream.
335
00:18:34,200 --> 00:18:37,000
Summarizing an email thread is a bounded task.
336
00:18:37,000 --> 00:18:40,800
The model reads the thread, identifies key points and produces a short summary.
337
00:18:40,800 --> 00:18:45,200
It doesn't need to know the history of email protocols or the cultural significance of the subject line.
338
00:18:45,200 --> 00:18:48,600
It just needs to extract information from a document you already have.
339
00:18:48,600 --> 00:18:50,400
Classification is even simpler.
340
00:18:50,400 --> 00:18:53,200
Is this document a contract a memo or an invoice?
341
00:18:53,200 --> 00:18:55,800
A small model can make that determination with high accuracy
342
00:18:55,800 --> 00:18:58,600
because the patterns are consistent and the context is local.
343
00:18:58,600 --> 00:19:02,600
The shift from one model to a model portfolio is what Microsoft itself is pursuing.
344
00:19:02,600 --> 00:19:05,600
The company's roadmap documents describe a hybrid AI approach
345
00:19:05,600 --> 00:19:08,400
where cloud hosted co-pilot handles large-scale reasoning
346
00:19:08,400 --> 00:19:14,600
and smaller task-specific models run closer to the user for speed, privacy, and offline resilience.
347
00:19:14,600 --> 00:19:16,200
This isn't a fringe experiment.
348
00:19:16,200 --> 00:19:19,400
It's the stated direction of the platform you're already paying for.
349
00:19:19,400 --> 00:19:23,000
There's a practical dimension to this that often gets lost in benchmark discussions.
350
00:19:23,000 --> 00:19:26,200
When you deploy in SLM, you're not just getting a cheaper model.
351
00:19:26,200 --> 00:19:29,000
You're getting a model that can be fine-tuned on your own data
352
00:19:29,000 --> 00:19:33,400
without requiring a cluster of A100 GPUs and a team of research scientists.
353
00:19:33,400 --> 00:19:39,000
A 3 billion parameter model can be fine-tuned on a single consumer grade GPU in hours, not days.
354
00:19:39,000 --> 00:19:42,600
That means your organization specific terminology, your document templates,
355
00:19:42,600 --> 00:19:46,600
your compliance language, and your brand voice can be embedded into the model
356
00:19:46,600 --> 00:19:48,800
without a six-figure training budget.
357
00:19:48,800 --> 00:19:52,600
The frontier models you access through APIs can't be fine-tuned in this way.
358
00:19:52,600 --> 00:19:57,000
You get what Microsoft or OpenAI built adapted through prompting and retrieval
359
00:19:57,000 --> 00:20:00,400
but never truly customized to your organization specific patterns.
360
00:20:00,400 --> 00:20:03,200
This customizability has security implications too.
361
00:20:03,200 --> 00:20:08,200
When you run an SLM locally, you control the model weights, the inference code, the logging, and the update cadence.
362
00:20:08,200 --> 00:20:12,600
You don't depend on a vendor's moderation layer or their interpretation of safety guidelines.
363
00:20:12,600 --> 00:20:17,000
You can implement your own content filters, your own data loss prevention, and your own audit trails.
364
00:20:17,000 --> 00:20:21,000
For organizations in regulated industries that have been burned by cloud provider policy changes,
365
00:20:21,000 --> 00:20:24,200
this control isn't paranoia, it's operational necessity.
366
00:20:24,200 --> 00:20:28,600
And that brings us to the most important family of SLMs in the Microsoft ecosystem,
367
00:20:28,600 --> 00:20:32,000
the models that are specifically designed to make this hybrid architecture real.
368
00:20:32,000 --> 00:20:36,000
The five family deep dive, Microsoft's five family of small language models
369
00:20:36,000 --> 00:20:38,800
is the clearest evidence that the company is serious about this shift.
370
00:20:38,800 --> 00:20:41,600
These aren't third-party models that happen to work on Azure.
371
00:20:41,600 --> 00:20:45,000
They're built by Microsoft Research, optimized for Microsoft's own platforms,
372
00:20:45,000 --> 00:20:49,800
and positioned as the default choice for cost-sensitive and latency critical workloads
373
00:20:49,800 --> 00:20:52,400
inside the Microsoft ecosystem.
374
00:20:52,400 --> 00:20:54,800
The current generation starts with 5-3 mini.
375
00:20:54,800 --> 00:21:00,400
It has roughly 3.8 billion parameters and was trained on 3.3 trillion tokens.
376
00:21:00,400 --> 00:21:04,400
That training scale relative to its size is part of why it punches above its weight.
377
00:21:04,400 --> 00:21:07,400
Microsoft didn't just shrink a large model, they trained a small model
378
00:21:07,400 --> 00:21:11,600
with the same data quality and curriculum techniques that make large models capable.
379
00:21:11,600 --> 00:21:14,800
The result is a model that, according to Microsoft's technical reports,
380
00:21:14,800 --> 00:21:19,200
achieved 69% on the massive multitask language understanding benchmark and scores,
381
00:21:19,200 --> 00:21:24,600
8.38 on the empty bench evaluation for instruction following and conversational quality.
382
00:21:24,600 --> 00:21:28,200
Those numbers put it in the same tier as GPT 3.5 class models,
383
00:21:28,200 --> 00:21:30,200
despite being small enough to run on a phone.
384
00:21:30,200 --> 00:21:33,400
Then there's 5-3 small at roughly 7 billion parameters,
385
00:21:33,400 --> 00:21:36,000
and 5-3 medium at roughly 14 billion.
386
00:21:36,000 --> 00:21:39,400
As the parameter count increases, the capability increases predictably.
387
00:21:39,400 --> 00:21:44,200
5-3 small reaches 75% on MMLU and 8.7 on empty bench.
388
00:21:44,200 --> 00:21:47,200
5-3 medium hits 78% and 8.9.
389
00:21:47,200 --> 00:21:51,200
Microsoft reports that 5-3 small and medium outperform same class competitors
390
00:21:51,200 --> 00:21:56,200
like Lama 3 at similar sizes and approach the performance of much larger models on specific benchmarks.
391
00:21:56,200 --> 00:21:59,200
The later 5-3.5 variants extend this line further.
392
00:21:59,200 --> 00:22:03,200
5-3.5 mini improves multilingual capability significantly,
393
00:22:03,200 --> 00:22:07,200
jumping from 47.3 to 55.4 on multilingual MMLU.
394
00:22:07,200 --> 00:22:11,200
5-3.5 MOE uses a mixture of experts architecture
395
00:22:11,200 --> 00:22:18,200
with 16 sets of 3.8 billion parameters activating roughly 6.6 billion parameters per forward pass.
396
00:22:18,200 --> 00:22:26,200
This design delivers performance that Microsoft describes as reaching above 90% of GPT 4/0 mini's average performance across language benchmarks,
397
00:22:26,200 --> 00:22:31,200
while outperforming similarly sized open source models like Lama 3.1 and Mixtral.
398
00:22:31,200 --> 00:22:35,200
There's also 5-3 vision, a 4.2 billion parameter multi-modal model
399
00:22:35,200 --> 00:22:40,200
that can read and reason over images, charts, diagrams and text within images.
400
00:22:40,200 --> 00:22:43,200
In M365 workloads this matters more than it might see at first.
401
00:22:43,200 --> 00:22:47,200
Excel screenshots, PowerPoint slides, scanned PDFs, whiteboard photos.
402
00:22:47,200 --> 00:22:50,200
These are everyday artifacts in enterprise work.
403
00:22:50,200 --> 00:22:56,200
A model that can interpret a chart from an image and summarise it in text is doing real work not demonstrating a party trick.
404
00:22:56,200 --> 00:23:01,200
What makes the 5 family particularly relevant for co-pilot isn't just the benchmark scores.
405
00:23:01,200 --> 00:23:06,200
It's the deployment profile. These models are designed to run efficiently on phones, laptops and edge devices.
406
00:23:06,200 --> 00:23:11,200
They're available through Azure AI Studio and Azure Machine Learning with simplified deployment, scaling and monitoring.
407
00:23:11,200 --> 00:23:16,200
And Microsoft explicitly markets them as the most capable and cost-effective models in their size class,
408
00:23:16,200 --> 00:23:20,200
outperforming models of the same or next size up on key benchmarks.
409
00:23:20,200 --> 00:23:25,200
This is the model portfolio that Microsoft wants you to use for the bulk of your AI workloads.
410
00:23:25,200 --> 00:23:30,200
Not because the company has given up on large models, but because Microsoft recognises what the research confirms,
411
00:23:30,200 --> 00:23:35,200
different tasks need different tools, and most enterprise tasks don't need the biggest tool in the box.
412
00:23:35,200 --> 00:23:40,200
It's worth pausing on the training methodology because it explains why 5 punches above its weight.
413
00:23:40,200 --> 00:23:47,200
Microsoft Research didn't simply compress a large model into a smaller one, which is the naive approach that usually produces mediocre small models.
414
00:23:47,200 --> 00:23:56,200
Instead, they used what they call textbook quality training data, carefully curated, high quality synthetic data sets designed to teach reasoning patterns rather than memorization.
415
00:23:56,200 --> 00:24:03,200
The result is a model that learnt how to think from a compact, well structured curriculum rather than one that tried to memorize the entire internet.
416
00:24:03,200 --> 00:24:10,200
This pedagogical approach is why a 3.8 billion parameter model can rival a 175 billion parameter model on reasoning tasks,
417
00:24:10,200 --> 00:24:12,200
even though it would lose badly on trivia.
418
00:24:12,200 --> 00:24:16,200
For enterprise architects, this training philosophy has practical implications.
419
00:24:16,200 --> 00:24:22,200
A model trained on structured, high quality data is often more predictable than one trained on massive, noisy data sets.
420
00:24:22,200 --> 00:24:26,200
It hallucinates less on routine tasks because it learnt patterns rather than facts.
421
00:24:26,200 --> 00:24:31,200
It follows instructions more precisely because it's training emphasise compliance with explicit prompts.
422
00:24:31,200 --> 00:24:36,200
It's easier to fine tune because the base model hasn't been saturated with conflicting information from the open web.
423
00:24:36,200 --> 00:24:38,200
But capability claims are easy.
424
00:24:38,200 --> 00:24:43,200
Let's look at the actual numbers because the benchmark story is more nuanced than a simple win-loss record.
425
00:24:43,200 --> 00:24:47,200
Benchmarks, when 3.8 billion parameters outperform GPT-4.
426
00:24:47,200 --> 00:24:52,200
Comparing 5-3 to GPT-4 isn't a simple question of which model is better.
427
00:24:52,200 --> 00:24:54,200
It's a question of which model is better for which task.
428
00:24:54,200 --> 00:25:00,200
And on the tasks that make up the majority of Microsoft 365 work, the small model is often the right choice.
429
00:25:00,200 --> 00:25:02,200
Let's start with the academic benchmarks.
430
00:25:02,200 --> 00:25:08,200
On the MMLU test, which measures broad knowledge across dozens of subjects, GPT-4 class models score well above 80%,
431
00:25:08,200 --> 00:25:11,200
FI-3 mini scores 69%, that's a meaningful gap.
432
00:25:11,200 --> 00:25:14,200
And it reflects the fundamental tradeoff of small models.
433
00:25:14,200 --> 00:25:16,200
They don't store as much factual knowledge.
434
00:25:16,200 --> 00:25:26,200
Microsoft acknowledges this explicitly in their technical reports, noting that 5-3's limited parameter capacity shows up as weaker performance on knowledge-intensive tasks like trivia-QA.
435
00:25:26,200 --> 00:25:29,200
But here's the critical insight for enterprise AI.
436
00:25:29,200 --> 00:25:32,200
Most M365 tasks aren't knowledge quizzes.
437
00:25:32,200 --> 00:25:35,200
They're reasoning tasks over content the user already has.
438
00:25:35,200 --> 00:25:39,200
When co-pilot summarizes a meeting transcript, the model doesn't need to know world history.
439
00:25:39,200 --> 00:25:46,200
It needs to understand the structure of conversation, identify decisions, extract action items and attribute them to participants.
440
00:25:46,200 --> 00:25:50,200
That's an instruction following and summarization task, not a general knowledge task.
441
00:25:50,200 --> 00:25:53,200
And on those tasks, the gap closes dramatically.
442
00:25:53,200 --> 00:26:01,200
On MTBench, which measures conversational quality and instruction following, 5-3 mini scores 8.38, that's firmly in GPT-3.5 territory.
443
00:26:01,200 --> 00:26:08,200
For the email drafting, reply generation and document summarization that makes up the bulk of daily co-pilot usage, that level of performance is sufficient.
444
00:26:08,200 --> 00:26:13,200
The model can follow your formatting preferences, adopt your tone and produce coherent output.
445
00:26:13,200 --> 00:26:16,200
It might not win a trivia contest against GPT-4, but that's not the job.
446
00:26:16,200 --> 00:26:19,200
The 5-3.5 MOE variant pushes even further.
447
00:26:19,200 --> 00:26:26,200
With its mixture of experts' design, it reaches above 90% of GPT-4O mini's average performance on language benchmarks.
448
00:26:26,200 --> 00:26:34,200
In some specific areas, like the math benchmark for mathematical reasoning, 5-3.5 mini actually beats GPT-4 in certain aggregations.
449
00:26:34,200 --> 00:26:40,200
For Excel formula generation, data explanation and numerical analysis, tasks where co-pilot is increasingly used, this matters.
450
00:26:40,200 --> 00:26:42,200
The multi-model story is equally relevant.
451
00:26:42,200 --> 00:26:50,200
5-3 vision handles charts, diagrams and text in images with competence that Microsoft describes as competitive or superior to comparable scale models.
452
00:26:50,200 --> 00:26:58,200
In the 5-3 technical report, the company highlights that safety post-training significantly improves responsible AI performance across vision language benchmarks.
453
00:26:58,200 --> 00:27:06,200
For an enterprise deploying AI that will read screenshots of dashboards, scan invoices and interpret presentation slides, this isn't a novelty.
454
00:27:06,200 --> 00:27:10,200
It's a core requirement. The real comparison isn't a single score. It's a task matrix.
455
00:27:10,200 --> 00:27:16,200
For routine email summarization in Outlook, 5-3 mini is good enough. For simple drafting and paraphrasing in word, it's good enough.
456
00:27:16,200 --> 00:27:23,200
For meeting recap and action item extraction in teams, it's good enough. For basic data description and formula assistance in Excel, it's good enough.
457
00:27:23,200 --> 00:27:31,200
For all of these tasks, the small model delivers acceptable quality at a fraction of the cost and latency. GPT-4 remains the right choice for the exceptions.
458
00:27:31,200 --> 00:27:38,200
Complex multi-document synthesis where nuance matters. Highly strategic documents where subtle misinterpretation carries risk,
459
00:27:38,200 --> 00:27:42,200
legal and compliance drafting where the models broader knowledge-based catches edge cases.
460
00:27:42,200 --> 00:27:47,200
Cross-meeting analysis spanning 10 related transcripts where implicit patterns need to be detected.
461
00:27:47,200 --> 00:27:53,200
These are high stakes, low volume tasks where the premium model earns its keep. The smart architecture doesn't ask which model is better.
462
00:27:53,200 --> 00:28:02,200
It asks which model is appropriate and the research is clear. For the high volume narrow repeatable tasks that consume most of your co-pilot budget, the small model is not a compromise.
463
00:28:02,200 --> 00:28:17,200
It's the correct specification. There's another benchmark dimension that matters for M365 specifically. Context length. 5-3.5 mini supports up to 128,000 tokens of context, which is 4 times the 32,000 token limit of some GPT-4 configurations.
464
00:28:17,200 --> 00:28:31,200
For document heavy workflows, analyzing a 50-page word contract, summarizing a 100-message email thread or querying across multiple Excel tabs, that longer context window means the SLM can ingest the full document in one pass
465
00:28:31,200 --> 00:28:45,200
rather than chunking it into smaller pieces and losing coherence. Combined with the much lower cost per token, this context advantage makes 5-3 variants particularly well suited to the long document scenarios that are common in legal, compliance and executive assistant workflows.
466
00:28:45,200 --> 00:28:59,200
The multimodal story also bears expanding. 5-3 visions ability to read charts, diagrams and text in images isn't just a technical curiosity. In Excel, users frequently take screenshots of pivot tables or charts and ask for analysis.
467
00:28:59,200 --> 00:29:09,200
In PowerPoint, presenters embed diagrams that contain as much information as the slide text. In Teams, Whiteboard Photos from Hybrid Meetings capture decisions that never made it into type notes.
468
00:29:09,200 --> 00:29:17,200
A model that can interpret these visual elements and incorporate them into summaries, answers or next step recommendations is doing work that a text only models simply cannot do.
469
00:29:17,200 --> 00:29:22,200
And 5-3 vision does this at a scale in cost that makes it deployable for routine use rather than special occasions.
470
00:29:22,200 --> 00:29:30,200
And when you combine that specification with the economics of local deployment, the case becomes overwhelming. Cost and latency, the numbers nobody talks about.
471
00:29:30,200 --> 00:29:36,200
We've already touched on the pricing gap, but let's put it in deployment terms that an IT architect can take to a board meeting.
472
00:29:36,200 --> 00:29:49,200
Because the difference between cloud API pricing and self-hosted economics is where the real transformation happens. At cloud API rates, GPT-4 runs at approximately $30 per million tokens for input and $60 per million tokens for output.
473
00:29:49,200 --> 00:29:59,200
Fi 3.5 mini runs at approximately $0.10 per million tokens for both input and output. That's a 300-1 difference on input and a 600-1 difference on output.
474
00:29:59,200 --> 00:30:10,200
If your organization processes 50 million tokens per month through co-pilot, a conservative estimate for a mid-sized enterprise, the cloud API cost alone is $1500 to $3,000 monthly at GPT-4 rates.
475
00:30:10,200 --> 00:30:16,200
At Fi 3.5 mini rates, it's $5, but self-hosted economics are where the gap becomes transformative.
476
00:30:16,200 --> 00:30:23,200
When you deploy an SLM on your own as your local infrastructure or even commodity GPU hardware, the per token marginal cost approaches zero.
477
00:30:23,200 --> 00:30:29,200
You're paying for the server, the electricity, and the operator time. The inference itself is effectively free at scale.
478
00:30:29,200 --> 00:30:38,200
Research on enterprise cost analysis notes that self-hosted SLM economics can widen the cost advantage to 100 times or more versus cloud LLM usage.
479
00:30:38,200 --> 00:30:46,200
For organizations processing at least 50 million tokens per month, on-premise deployment breaks even in months. The latency numbers are equally stark.
480
00:30:46,200 --> 00:30:52,200
When Fi 3 mini runs on local hardware or edge devices, it delivers first responses in 10 to 50 milliseconds.
481
00:30:52,200 --> 00:30:59,200
On an iPhone 14 with full-bit quantization, it generates over 12 tokens per second using only 1.8 gigabytes of memory.
482
00:30:59,200 --> 00:31:07,200
Cloud hosted GPT-4 by contrast typically shows first token latency of 300 to 2,000 milliseconds before generating any useful output.
483
00:31:07,200 --> 00:31:12,200
That gap is the difference between a tool that feels instant and a tool that feels delayed.
484
00:31:12,200 --> 00:31:15,200
In GPU environments, the throughput advantage compounds.
485
00:31:15,200 --> 00:31:21,200
Because SLMs are smaller, they can serve many more concurrent requests per GPU at a given latency target.
486
00:31:21,200 --> 00:31:32,200
For massive fan-out workloads like compliance scanning across a SharePoint tenant or always on meeting summarization for every team's call, this throughput difference means fewer GPUs, less infrastructure and lower total cost of ownership.
487
00:31:32,200 --> 00:31:46,200
The research documents enterprise usage patterns that exploit these advantages. Teared model routing, where the system starts with an SLM and escalates to a Frontier model only when confidence or complexity demands it routinely delivers 40 to 90% reductions in total LLM spend.
488
00:31:46,200 --> 00:31:55,200
Hybrid, draft and refine patterns, where an SLM generates the first pass in a Frontier model audits or refines a subset, capture most of the quality at a fraction of the cost.
489
00:31:55,200 --> 00:32:05,200
These aren't theoretical optimizations, they are deployment patterns that enterprises are already using and they are patterns that become mandatory once co-pilot moves from pilot to production.
490
00:32:05,200 --> 00:32:10,200
A pilot with 50 users can absorb Frontier model costs, production with 50,000 users cannot.
491
00:32:10,200 --> 00:32:18,200
The energy efficiency story adds another dimension to the cost discussion. Frontier models run on massive GPU clusters that consume enormous amounts of electricity.
492
00:32:18,200 --> 00:32:27,200
Every inference request carries a carbon footprint that while small individually aggregates into a significant environmental cost at enterprise scale.
493
00:32:27,200 --> 00:32:39,200
SLMs by contrast run on a fraction of the compute. A single modest GPU can serve hundreds of concurrent SLM requests with power consumption that wouldn't even register on a data center's cooling budget.
494
00:32:39,200 --> 00:32:49,200
For organizations with sustainability commitments or carbon reporting requirements, this efficiency isn't a side benefit, it's a measurable line item advantage, which brings us to the most important architectural inside of all.
495
00:32:49,200 --> 00:32:56,200
This isn't about replacing GPT-4 with 5-3, it's about building a system that knows which model to use for which task.
496
00:32:56,200 --> 00:32:59,200
The tiered architecture, not replacement but rooting.
497
00:32:59,200 --> 00:33:08,200
The future of enterprise AI isn't one model, it's a portfolio of models orchestrated by a rooting layer that matches each task to the smallest model that can handle it competently.
498
00:33:08,200 --> 00:33:19,200
Microsoft understands this. The company's March 2026 reorganization of co-pilot into a single organization spanning experience platform applications and AI models was explicitly designed to enable this tiered future.
499
00:33:19,200 --> 00:33:25,200
The vision that emerges from Microsoft's documentation and community proposals is a layered assistant architecture.
500
00:33:25,200 --> 00:33:32,200
At the baseline tier you get simple app embedded chat, basic summaries and straightforward drafting in word, outlook and teams.
501
00:33:32,200 --> 00:33:40,200
This is the free or low cost tier and it's exactly where S&M's shine. The tasks are narrow, the context is local and the quality bar is high but not existential.
502
00:33:40,200 --> 00:33:51,200
At the context tier, co-pilot gains memory and formatting intelligence. It learns your writing style, remembers your project context and operates within a defined scope like a notebook focused on specific files.
503
00:33:51,200 --> 00:33:59,200
This tier requires more capability than the baseline but still operates within bounded parameters that a small or medium SLM can handle.
504
00:33:59,200 --> 00:34:05,200
At the identity tier, co-pilot becomes persistent across devices, retaining long term memory of preferences, projects and workflows.
505
00:34:05,200 --> 00:34:12,200
This is where the frontier model becomes more relevant because cross app reasoning and complex personalization demand broader capability.
506
00:34:12,200 --> 00:34:20,200
At the operator tier, co-pilot acts as a full workflow manager, orchestrating multi-step processes across word, Excel, PowerPoint, Outlook and third party systems.
507
00:34:20,200 --> 00:34:24,200
This is high complexity, high stakes automation that justifies frontier model investment.
508
00:34:24,200 --> 00:34:35,200
The business implication is clear, different users need different tiers, different tiers need different models and charging everyone for the operator tier while delivering baseline tasks is exactly the structural floor we're diagnosing.
509
00:34:35,200 --> 00:34:38,200
Microsoft's own product moves confirm this direction.
510
00:34:38,200 --> 00:34:47,200
Co-pilot notebooks, which allow users to create AI-powered notebooks focused on curated sets of files, represent a mid-tier capability that benefits from scoped, smaller models.
511
00:34:47,200 --> 00:34:58,200
Cross app orchestration features where co-pilot can schedule meetings and outlook from Teams chat or push drafts directly into mail, show the platform evolving toward tiered intelligence rather than uniform capability.
512
00:34:58,200 --> 00:35:01,200
For enterprise architects, this means the design question changes.
513
00:35:01,200 --> 00:35:07,200
Instead of asking which model should we standardize on, you ask which model should handle which workload and how do we route between them.
514
00:35:07,200 --> 00:35:16,200
The answer is a tiered architecture where SLMs handle the bulk of routine traffic and frontier models serve as escalation targets for complexity, ambiguity and high stakes output.
515
00:35:16,200 --> 00:35:29,200
This is the shift from model selection to model orchestration and it's the shift that transforms co-pilot from an expensive chat feature into a scalable, governable cost-controlled AI platform but orchestration doesn't just happen in the cloud.
516
00:35:29,200 --> 00:35:31,200
The real revolution is where these models run.
517
00:35:31,200 --> 00:35:39,200
The orchestration layer, how co-pilot actually routes tasks. When most people imagine a tiered AI architecture, they picture a simple flow chart.
518
00:35:39,200 --> 00:35:45,200
Small tasks go left, complex tasks go right. But in reality, the orchestration layer is where the engineering gets interesting.
519
00:35:45,200 --> 00:35:52,200
Because routing isn't just about task type, it's about confidence, risk, cost, latency and data classification all at once.
520
00:35:52,200 --> 00:35:58,200
The standard Microsoft 365 co-pilot architecture today follows a predictable pipeline, a user sensor prompt.
521
00:35:58,200 --> 00:36:01,200
The system enriches that prompt with context from the Microsoft graph.
522
00:36:01,200 --> 00:36:13,200
Emails, chats, files, calendar entries, meeting transcripts. Then a large language model generates a response, post-processing checks refine the answer, security trimming ensures the user only sees content they're authorized to access.
523
00:36:13,200 --> 00:36:19,200
And the response returns to the app. In a tiered architecture that middle step, the LLM generation becomes a routing decision.
524
00:36:19,200 --> 00:36:27,200
The system doesn't just hand every request to GPT-4. It first evaluates what the user is asking, what data is involved and what quality threshold the task demands.
525
00:36:27,200 --> 00:36:33,200
Intent detection is the first filter. Is the user asking for a simple summary, a classification, a routine draft?
526
00:36:33,200 --> 00:36:38,200
Or are they asking for complex reasoning across multiple documents, creative writing or strategic analysis?
527
00:36:38,200 --> 00:36:48,200
Simple intents root to SLMs immediately. Complex intents might still root to an SLM for an initial pass with a frontier model serving as a verification layer, policy-based routing adds the governance layer.
528
00:36:48,200 --> 00:36:55,200
Your organization might define that any request involving legal documents, HR records or financial data must stay within your local infrastructure.
529
00:36:55,200 --> 00:37:00,200
These policies don't depend on what the user is asking. They depend on what data the prompt touches.
530
00:37:00,200 --> 00:37:11,200
If the Microsoft Graph-Grounding pulls in files from a restricted SharePoint library, the routing layer directs the request to your locally hosted SLM regardless of task complexity.
531
00:37:11,200 --> 00:37:27,200
Confidence scoring provides the feedback loop. When an SLM generates a response, the system can evaluate its own confidence, no confidence outputs, ambiguous classification, uncertain summaries, requests that fall outside the model's training distribution can be escalated to a frontier model for refinement.
532
00:37:27,200 --> 00:37:34,200
This hybrid draft and refined pattern captures most of the cost and latency savings while preserving quality for edge cases.
533
00:37:34,200 --> 00:37:39,200
The research on enterprise routing architectures describes this as the increasingly dominant practical pattern.
534
00:37:39,200 --> 00:37:47,200
Organizations use SLMs for classification, extraction, routing, frequently asked questions, document tagging and workflow automation.
535
00:37:47,200 --> 00:37:54,200
They reserve LLMs for open-ended customer interactions, complex reasoning, cross-document synthesis, creative drafting and expert assistance.
536
00:37:54,200 --> 00:38:01,200
The boundary between these tiers isn't fixed. It's configurable based on your risk tolerance, your cost constraints and your quality requirements.
537
00:38:01,200 --> 00:38:04,200
Microsoft's own technical positioning points in this direction.
538
00:38:04,200 --> 00:38:13,200
The company describes SLMs as the practical alternative where efficiency and device local deployment matter while acknowledging that frontier models still handle the most demanding reasoning.
539
00:38:13,200 --> 00:38:18,200
The natural architecture that emerges from this positioning is exactly the tiered routing layer we're describing.
540
00:38:18,200 --> 00:38:26,200
For developers building on Azure, the tooling to implement this is already available. Azure AI Foundry provides the model catalog, evaluation tools and deployment pipelines.
541
00:38:26,200 --> 00:38:30,200
Azure ARC extends these capabilities to on-premises and multi-cloud environments.
542
00:38:30,200 --> 00:38:37,200
And the RAC capabilities available as Azure ARC extensions give you end-to-end retrieval pipelines that can run entirely on local infrastructure,
543
00:38:37,200 --> 00:38:42,200
grounding SLM responses in your own documents, without ever sending data to the public cloud.
544
00:38:42,200 --> 00:38:53,200
The key insight is that routing isn't an add-on, it's the architecture. Without it, you're either overpaying for frontier models on simple tasks or your underpowering complex tasks with small models.
545
00:38:53,200 --> 00:38:58,200
With it, you get the right model for every job and you maintain the governance controls that make enterprise deployment possible.
546
00:38:58,200 --> 00:39:05,200
There's a failure mode in routing architectures that deserves mention because it's the mistake most organizations make in their first implementation.
547
00:39:05,200 --> 00:39:13,200
They build the routing layer as a simple if-then-else system based on task type and they discover that reality is messier than their categories.
548
00:39:13,200 --> 00:39:19,200
A request that looks like a simple summary might actually require reasoning over a legal document with subtle implications.
549
00:39:19,200 --> 00:39:24,200
A request that looks like complex analysis might turn out to be a routine extraction from a well-structured form.
550
00:39:24,200 --> 00:39:30,200
Static routing rules fail on these edge cases because they don't inspect the actual content or the actual data involved.
551
00:39:30,200 --> 00:39:45,200
The mature routing architectures solve this with dynamic evaluation. The system doesn't just look at the task type, it looks at the data classification, the document complexity, the user's role, the historical accuracy of each model on similar requests and the real-time cost and latency constraints.
552
00:39:45,200 --> 00:39:54,200
This multi-factor routing is more complex to implement but it's also more robust. It adapts to your organization's actual usage patterns rather than forcing your usage into predefined buckets.
553
00:39:54,200 --> 00:40:04,200
Another implementation detail that matters is request batching and caching. High frequency tasks like document classification or entity extraction often receive identical or near identical inputs repeatedly.
554
00:40:04,200 --> 00:40:10,200
A routing layer that caches SLM outputs for common requests can eliminate inference costs entirely for those cases.
555
00:40:10,200 --> 00:40:16,200
A routing layer that batches similar requests together can improve GPU utilization and reduce per request latency.
556
00:40:16,200 --> 00:40:30,200
These optimizations are only available when you own the routing infrastructure rather than relying on a cloud provider's opaque scheduling. For Microsoft 365 specifically, the routing layer will likely emerge as part of the co-pilot platform itself rather than as a custom build.
557
00:40:30,200 --> 00:40:40,200
Microsoft's tiered architecture vision, described in road map and community proposal documents explicitly contemplates different capability tiers powered by different model families.
558
00:40:40,200 --> 00:40:47,200
As this platform matures, the routing decisions that today require custom engineering will become configurable policies in the admin console.
559
00:40:47,200 --> 00:40:53,200
Organizations that understand the routing concepts now will be ready to configure these policies effectively when they arrive.
560
00:40:53,200 --> 00:41:01,200
Organizations that don't will default to the most expensive tier for everything. But the most powerful form of this architecture doesn't just root between models in the cloud.
561
00:41:01,200 --> 00:41:12,200
It runs the small models exactly where your data already lives as your local and the sovereign edge as your local is Microsoft's answer to a question that regulated industries have been asking for years.
562
00:41:12,200 --> 00:41:26,200
Can we get the benefits of cloud AI without sending our data to the cloud? The answer is yes. But the implementation matters as your local is first party managed infrastructure that runs in your own data center or edge site controlled through the same Azure management plan you already use.
563
00:41:26,200 --> 00:41:40,200
It's not a separate product with separate tooling. It's a zure just located where you need it. That distinction is important because it means your existing operational skills, your existing policies and your existing governance frameworks all apply without retraining your team.
564
00:41:40,200 --> 00:41:45,200
The platform supports three connectivity modes connected mode gives you full cloud integration with Azure services.
565
00:41:45,200 --> 00:42:01,200
Intermittently connected mode allows periodic synchronization for updates and telemetry and fully disconnected mode currently moving toward general availability lets you run AI workloads in air gaped or sovereignty restricted environments with no network dependency on Microsoft's public cloud at all.
566
00:42:01,200 --> 00:42:13,200
For small language models this deployment profile is transformative a five three mini model running on Azure local inside your facility delivers sub 50 millisecond responses to requests that never leave your network boundary.
567
00:42:13,200 --> 00:42:23,200
Your contracts your patient records your financial transactions your classified documents they can all be processed by AI without crossing a jurisdictional line. The integration stack is designed for this specifically.
568
00:42:23,200 --> 00:42:35,200
Azure arc enables Kubernetes clusters on Azure local to be managed with the same tools you use for cloud clusters. Azure AI foundry local brings model lifecycle management evaluation and monitoring to your on premises environment.
569
00:42:35,200 --> 00:42:49,200
AKS edge essentials extends container orchestration to branch offices factory floors and remote sites and the SLM side car pattern documented for Azure app service but applicable anywhere lets you deploy a web application with its own embedded model in a single network boundary.
570
00:42:49,200 --> 00:43:04,200
Research on Azure local use cases highlights the industries where this matters most manufacturing facilities use operator co pilots for machinery troubleshooting with SLM's interpreting natural language queries about machine states and maintenance logs without sending production data to the cloud.
571
00:43:04,200 --> 00:43:12,200
Energy and utility companies run anomaly detection and strategic planning models on infrastructure that stays within their operational technology perimeter.
572
00:43:12,200 --> 00:43:19,200
Government and defense organizations deploy fully disconnected clusters for policy assistance and secure knowledge bases in classified environments.
573
00:43:19,200 --> 00:43:28,200
The pattern across all of these deployments is the same the data is too sensitive too large or too tightly coupled with on premises systems to move to the cloud.
574
00:43:28,200 --> 00:43:45,200
Agency requirements are too strict to tolerate around trip to a distant data center the compliance requirements are too explicit to allow cross border processing and the SLM is exactly the right size to run on infrastructure they already control Azure local makes this practical by eliminating the operational gap between cloud AI and local AI.
575
00:43:45,200 --> 00:43:56,200
You're not cobbling together open source tools and praying they integrate you're using Microsoft's first party platform Microsoft's model catalog and Microsoft security framework the model just happens to be running in your building.
576
00:43:56,200 --> 00:44:17,200
The hardware requirements for running SLM's on Azure local are also more accessible than many organizations assume a dedicated Nvidia GPU with 12 to 24 gigabytes of VRM is sufficient for professional speed local inference of models like 5 3 mini and 5 3 small for larger deployments serving multiple concurrent uses a modest server with multiple GPUs can handle hundreds of simultaneous requests.
577
00:44:17,200 --> 00:44:29,200
And because SLM's don't require the massive GPU clusters that frontier models need the capital expenditure is comparable to a mid range database server rather than a supercomputer the Azure arc integration is what makes this manageable at scale.
578
00:44:29,200 --> 00:44:45,200
Your on premises Kubernetes clusters are managed through the same Azure portal you use for cloud resources your dev ops team applies updates monitors health and scales capacity using the same terraform templates and Azure CLI commands they already know the learning curve is real but it's incremental rather than revolutionary.
579
00:44:45,200 --> 00:44:57,200
And the new one is more extending existing skills rather than acquiring entirely new ones but the sovereignty story doesn't end at your firewall it extends to the legal jurisdictions that govern what you can and cannot do with your data.
580
00:44:57,200 --> 00:45:11,200
The EU data boundary inflex routing if you're operating in the European Union or if your organization serves EU customers the data sovereignty discussion isn't abstract it's governed by specific mechanisms with specific defaults that most administrators haven't fully reviewed.
581
00:45:11,200 --> 00:45:22,200
And the new data boundary is a commitment that personal data for commercial and public sector customers in the EU and FDA will be stored and processed within that geographic region with a limited set of necessary exceptions.
582
00:45:22,200 --> 00:45:33,200
It's a genuine structural investment by Microsoft completed for major cloud services in 2023 and 2024 and continuously refine since then but the boundary has gaps and in 2026 those gaps became active risks.
583
00:45:33,200 --> 00:45:50,200
And the most significant gap as of April 2026 Microsoft enabled it by default for all EU and FDA tenants when EU capacities constrained co pilot inference requests can be routed to data centers in the United States Canada or Australia Microsoft states that customer data
584
00:45:50,200 --> 00:46:11,200
remains in the EU that requests are encrypted in transit and that only limited to Donemey's data is stored outside the region for operational purposes for many organizations that explanation isn't sufficient processing personal data outside the EU triggers questions under the general data protection regulation about international transfers standard contractual clauses and transfer impact assessments.
585
00:46:11,200 --> 00:46:38,200
So a national data protection authority takes the view that inference processing constitutes data transfer then flex routing may require a documented legal basis that your organization hasn't established the mitigation is straightforward but requires action administrators can disable flex routing in the Microsoft 365 admin center under co pilot settings and data location but the default is on and many organizations deploy co pilot without reviewing this specific toggle assuming that the EU data boundary protects them comprehensively.
586
00:46:38,200 --> 00:47:05,200
The anthropic model integration creates a second gap that flex routing controls do not address when co pilot uses Claude models for certain capabilities those requests are processed on AWS infrastructure in the United States no setting in your Microsoft 365 admin center changes that location Microsoft enterprise data protection still apply no model training on your data encryption throughout but the jurisdictional location of processing is fixed for organizations where strict EU residency is mandatory
587
00:47:05,200 --> 00:47:34,200
the only mitigation is to ensure anthropic models remain disabled then there's been connected web search co pilot features that rely on web search root queries through services outside your tenant typically hosted in the United States Microsoft asserts that search queries aren't stored or used to profile your tenant but this is a processing activity outside your boundary that your privacy documentation may not cover Microsoft is expanding in country and regional inferencing to address these concerns by the end of 2026 the company plans to offer in country co pilot processing in 15 countries including
588
00:47:34,200 --> 00:47:55,200
Germany Italy Poland Spain Sweden Switzerland and others for the EU this takes the form of regional inferencing aligned with the EU data boundary commitments as this capacity expands the pressure to use flex routing decreases but the toggle remains the option to root outside the EU remains and the compliance risk remains until you explicitly configure it away.
589
00:47:55,200 --> 00:48:21,200
This is why local deployment on Azure local isn't just a performance optimization for EU organizations it's a compliance architecture when your SLM runs in your Frankfurt data center processing your German employee documents no flex routing toggle matters no anthropic model location matters no being web search rooting matters the data never leaves the building the jurisdiction is yours the control is yours for data protection offices this transforms the risk conversation from trust Microsoft's configuration to verify our own infrastructure.
590
00:48:21,200 --> 00:48:34,200
It's a different level of assurance and for organizations operating under sector regulations like the digital operational resilience act for financial services or national health privacy laws that level of assurance can be the difference between approved deployment and legal exposure.
591
00:48:34,200 --> 00:48:49,200
So the question becomes what does this look like specifically for the tools you employees use every day m365 local AI on your terms Microsoft 365 local is the emerging scenario that brings together everything we've discussed so far.
592
00:48:49,200 --> 00:49:18,200
It's the intersection of Azure local infrastructure small language models and your existing Microsoft 365 content operating under your governance rather than Microsoft's cloud defaults the concept is straight forward your enterprise content lives in Microsoft 365 SharePoint document libraries exchange mailboxes teams chat histories one drive files traditionally when co pilot processes that content it sends requests to Microsoft's cloud AI services with m365 local scenarios the content stays in your local environment.
593
00:49:18,200 --> 00:49:42,200
And the AI processing happens on your Azure local cluster using s lm's that you control this isn't full offline Microsoft 365 your tenants still synchronizes with Microsoft's cloud for identity licensing and core services but the AI layer the summarization the classification the drafting the extraction runs locally for organizations that have already invested in hybrid Microsoft 365 architectures this is a natural extension rather than a disruptive replacement.
594
00:49:42,200 --> 00:50:11,200
The scenarios that m365 local enables are exactly the high frequency low complexity tasks we've been discussing and employee opens outlook and asks co pilot to summarize an email thread instead of that request traveling to a Microsoft data center for processing it hits your local 5 3 model running on Azure local inside your facility the response returns in under 100 milliseconds the email content never leaves your network the summary is generated delivered and forgotten without a single bite crossing your perimeter in teams a manager asks for action items from a meeting transcript.
595
00:50:11,200 --> 00:50:39,200
The transcript is already stored in your local share point the s lm extracts tasks assigns owners and formats the output there is no cloud round trip no flex routing concern and no transfer assessment required for word and excel the pattern repeats document summarization style transformation simple formula explanation and data description all become local operations the heavy creative writing complex multi sheet analysis and strategic synthesis still root to frontier models in the cloud.
596
00:50:39,200 --> 00:51:01,200
But the routine work the 80% of requests that make up 20% of the cognitive load stays local Microsoft's documentation on on device and local deployment positions this as a strategic direction rather than a fringe feature the company describes a hybrid a approach where cloud hosted co pilot handles large scale reasoning and smaller models run closer to the user for speed privacy and offline resilience.
597
00:51:01,200 --> 00:51:30,200
While the specific product boundaries and licensing models for m 3 6 5 local are still emerging the architectural direction is clear Microsoft is building toward a world where not every co pilot request needs the cloud for it leaders the practical implication is that future m 3 6 5 AI controls won't just manage cloud co pilot policies they'll need to manage device eligibility model selection local data handling and endpoint governance the admin console expands from cloud toggles to hybrid orchestration and the skill set required shifts from SAS administration to hybrid AI platform manage.
598
00:51:30,200 --> 00:51:50,200
The offline resilience story deserves more attention than it typically gets most cloud first AI conversations assume reliable high bandwidth connectivity but enterprise reality is messier branch offices with DSL connections manufacturing plants in remote locations ships planes and field stations where connectivity is intermittent or nonexistent.
599
00:51:50,200 --> 00:52:19,200
Hospitals that maintain isolated networks for critical systems in all of these environments cloud dependent AI is either frustratingly slow or completely non functional local s l m's changes fundamentally a model running on an edge device or local server continues to operate when the one is down an engineer troubleshooting equipment in a basement can still query the maintenance co pilot a doctor in an isolated clinic can still summarize patient notes a soldier in a forward operating base can still access the policy assistant the research on Azure local explicitly highlights this resilience.
600
00:52:19,200 --> 00:52:48,200
As a core value proposition noting that local inference enables real time or near real time AI even when one links are slow or unavailable for Microsoft 365 specifically the offline scenario is particularly relevant because m 3 65 itself has hybrid capabilities organizations running exchange server in hybrid mode or share point server with cloud synchronization already manage the complexity of split workloads adding local AI processing to this stack is a natural extension rather than a radical departure the content is already in both places the AI just needs to be.
601
00:52:48,200 --> 00:53:02,200
The AI just needs to run whether content lives Microsoft's documentation frames this as a strategic direction describing s l m's as essential for scenarios were limited computing power low latency or keeping costs down is critical.
602
00:53:02,200 --> 00:53:17,200
The company positions on device and local deployment not as a downgrade from cloud AI but as a necessary complement that extends AI capability to places the cloud can't reach and for organizations that have already invested in hybrid Microsoft infrastructure the operational model is familiar is just a new workload on existing infrastructure.
603
00:53:17,200 --> 00:53:46,200
But this is in science fiction organizations are already doing it real world deployment patterns the research on Azure local and s l m deployments documents specific industries and use cases where this architecture is already in production these aren't pilot projects their operational systems handling real workloads in manufacturing operator co pilots interpret natural language queries about machine states procedures and alarms an operator on the plant floor asks why a particular line is showing a warning light the s l m running on an edge cluster inside the facility.
604
00:53:46,200 --> 00:54:12,200
Queries local maintenance logs and procedural documents then returns a diagnosis and recommended next steps the response arrives in under a second the production data never leaves the plant network and when the one connection is down the co pilot keeps working because it doesn't need one in regulated environments like government and defense policy assistance answer staff queries against internal regulatory manuals and legal frameworks the s l m is fine tuned on the organizations own documents.
605
00:54:12,200 --> 00:54:33,200
The rag pipeline indexes classified or sensitive documentation stored on sovereign infrastructure and because the entire stack runs on Azure local and disconnected mode the system meets air gap requirements without sacrificing modern AI capabilities in financial services local s l m's analyze transaction histories and customer profiles for pattern detection and risk assessment.
606
00:54:33,200 --> 00:55:02,200
The data is subject to strict localization laws that prohibit cloud processing the s l m provides analytical capability that would otherwise require manual review or expensive on premise traditional software and the organization maintains full control over model versions logging and data retention health care organizations use local s l m's for clinical notes summarization radiology report processing and patient record analysis patient privacy laws in most jurisdictions make cloud AI processing legally complex or impossible for identifiable health records.
607
00:55:02,200 --> 00:55:12,200
A locally deployed model running on hospital controlled infrastructure delivers the productivity benefits without the compliance risk the common pattern across all of these deployments is hybrid search and retrieval.
608
00:55:12,200 --> 00:55:29,200
The Azure arc extension for rag provides end to end pipelines for data ingestion vector index creation and retrieval APIs that integrate with language models it works with on premises and multi cloud data sources and it's designed specifically for the data sovereignty latency reduction and compliance requirements that drive local deployment decisions.
609
00:55:29,200 --> 00:55:47,200
For horizontal enterprise use cases the patterns are equally practical knowledge co pilots index weekies file shares CRM records and support tickets that must remain on premises project and proposal generation tools create first drafts grounded in past deliverables and internal templates stored on local file servers.
610
00:55:47,200 --> 00:56:16,200
Change management and training bots ingest HR and IT documentation locally giving staff conversational access to policies without requiring them to search through multiple portals these deployments share three characteristics they run on infrastructure the organization controls they process data that never leaves the organization's jurisdiction and they use small language models because the tasks are narrow enough that a small model is not just sufficient but optimal the retail and hospitality sector presents another compelling pattern in store associate co pilots run on small edge clusters at each location.
611
00:56:16,200 --> 00:56:37,200
Assisting staff with product information inventory queries and policy questions using store specific data and regional promotions customer facing kiosks use natural language interaction to guide shoppers with the privacy benefit that no conversation logs leave the device facilities management bots interpret building sensor data and maintenance logs to answer operator questions about alerts and historical behaviors.
612
00:56:37,200 --> 00:56:47,200
All of these use cases share common constraint the branch or site has limited it support intermittent connectivity and a requirement that sensitive customer or operational data stays on site.
613
00:56:47,200 --> 00:57:01,200
The SLM sidecar pattern originally documented for Azure app service has become a standard deployment template across these scenarios an application container and its embedded model run in the same pod or service plan communicating through internal network calls that never cross a perimeter.
614
00:57:01,200 --> 00:57:30,200
For line of business applications that need AI augmentation form automation document understanding context aware search across legacy ERP systems this pattern delivers capability without replatforming the entire system the SLM becomes an internal API endpoint that the existing application calls just like it would call a database or a caching layer the operational complexity is real running AI on premises requires capacity planning hardware lifecycle management Kubernetes operations and security hardening as your local mitigates much of this through management.
615
00:57:30,200 --> 00:57:52,200
So much of this through managed aspects but the organization still manages the physical environment the skills required span deaf ops ML ops and traditional IT infrastructure for many teams this is a learning curve but the alternative running everything through cloud frontier models is increasingly untenable for organizations with strict data controls unpredictable costs or latency requirements.
616
00:57:52,200 --> 00:58:21,200
The question isn't whether local deployment is more complex it's whether the benefits outweigh that complexity and for the use cases we're seeing in production the answer is increasingly yes which brings us to the last piece of the architecture because deploying models locally doesn't eliminate your security responsibilities it changes them the security and compliance architecture when you move AI processing from Microsoft's cloud to your own infrastructure the security model doesn't get simpler it gets different you trade reliance on Microsoft security operations for direct control over your own.
617
00:58:21,200 --> 00:58:50,200
And that trade is only valuable if you implement the controls correctly the first control is data classification and routing not all data is equally sensitive your public marketing materials can probably process through cloud AI without concern your board minutes your merger documents your patient records and your classified contracts cannot a tiered data classification system public internal sensitive highly sensitive drives the routing policy highly sensitive data processes exclusively on local sLM sensitive data might process on the
618
00:58:50,200 --> 00:59:19,200
local sLM's with optional cloud escalation for specific tasks public and internal data can use cloud services where latency or cost benefits exist the second control is encryption and access management data address and in transit around the sLM environment must be encrypted access to the model endpoints must be authenticated through your existing identity system not left as anonymous API's on your internal network and the principle of least privilege applies to both human users and service accounts that call the model the third control is logging retention and audit local
619
00:59:19,200 --> 00:59:37,200
deployment means you own the logs you determine how long prompt histories are retained you control whether outputs are stored for quality review and you integrate sLM usage into your existing data governance processes documenting which data the model accesses which versions are deployed and how evaluation artifacts are maintained.
620
00:59:37,200 --> 01:00:00,200
Microsoft's own security and compliance guidance for sLM emphasizes responsible AI post training the five three technical report documents substantial safety improvements across multiple benchmark categories after safety tuning and Azure AI content safety provides filtering and monitoring tools that can be deployed alongside your local models the research on data sovereignty best practices frames this as a foundational requirement.
621
01:00:00,200 --> 01:00:29,200
Organizations need robust encryption pseudonymization where appropriate regular audits and clear data processing agreements with any external providers when you're running your own sLM the external provider is gone but the governance requirement remains your now the provider and your auditors will hold you to the same standards they would hold Microsoft for organizations that already operate regulated on premises systems this isn't a new challenge it's an extension of existing practices the sLM becomes another workload in your compliance scope the novelty is that this workload can now deliver AI capability.
622
01:00:29,200 --> 01:00:58,200
The delivery AI capabilities that previously required cloud services the governance is familiar the capability is new there's an additional layer of security consideration specific to sLM that doesn't get enough attention because small models can be fine tuned and customized more easily than frontier models they also present a different attack surface a poisoned training data set whether introduced maliciously or through poor data curation can embed back doors or biases that are harder to detect in a smaller parameter space an attacker with access to your fine tuning pipeline can potentially influence model.
623
01:00:58,200 --> 01:01:05,200
It potentially influence model behavior in ways that wouldn't be feasible with a trillion parameter model hosted by a major cloud provider.
624
01:01:05,200 --> 01:01:27,200
This doesn't mean sLM is less secure it means the security model is different with frontier models your outsourcing security to Microsoft open AI or anthropic they control the training data the model weights the update cadence and the safety filters with local sLM's you own all of those responsibilities the trade off is control for effort you get complete visibility into what the model was trained on how it's behaving and what it's producing
625
01:01:27,200 --> 01:01:55,200
you also need the internal capability to verify and validate those things the research on Azure sLM deployment security emphasizes this point best practices include encrypting data address and in transit applying strong access control and authentication to local model endpoints configuring logging and retention consistent with local laws and integrating sLM usage into existing data governance processes these aren't optional extras their foundational requirements for any production deployment model versioning is another critical control
626
01:01:55,200 --> 01:02:23,200
when you deploy an sLM locally you decide when to update it you can test a new version in a staging environment before promoting it to production you can roll back if the new version produces different or worse output you can maintain multiple versions for different use cases or departments this level of control is impossible with cloud API models where the provider can update the model weights at any time without notifying you and where model versions are often just API endpoint aliases that point to whatever the provider currently considers the best model
627
01:02:23,200 --> 01:02:42,200
for regulated industries that require reproducibility and audit ability this control is essential a financial services firm that uses an AI model to flag suspicious transactions needs to be able to reproduce the models decision six months later during an audit if the model has been silently updated by the cloud provider reproducibility is impossible
628
01:02:42,200 --> 01:03:09,200
with a locally deployed version control sLM the firm can maintain the exact model weights the exact inference code and the exact input output pairs for as long as regulatory requirements demand so we've diagnosed the floor we've explored the fix we've looked at the architecture the deployment patterns and the security model the remaining question is how you put this together into a strategy your organization can actually execute building your model mixture strategy if you take one thing from this deep dive take this the goal isn't to replace GPT4 with five three
629
01:03:09,200 --> 01:03:31,200
the goal is to stop using a single model for every task and instead build a portfolio where each model handles the work it was designed for that's the model mixture strategy and it's how you turn copilot from a cost center into a competitive advantage the first step is establishing your performance ceiling before you can decide which tasks belong to small models you need to know what good looks like run your existing high value tasks through GPT4 or GPT4
630
01:03:31,200 --> 01:03:51,200
document the output quality the latency the cost per task and the user satisfaction this isn't wasted spend it's your baseline it tells you what the premium tier delivers and it gives you a target to match when you start rooting work to smaller models the second step is identifying your high volume repeatable workflows these are the tasks your employees perform dozens or hundreds of times per day
631
01:03:51,200 --> 01:04:20,200
email summarization meeting action item extraction document classification routine drafting and replies simple data extraction from structured forms these tasks have predictable inputs bounded outputs and consistent quality requirements their perfect candidates for s l m migration because the patterns are stable and the volume is high the research on enterprise cost analysis provides a clear framework for this identification process look for workflows that are narrow repetitive and high throughput tasks where good enough accuracy is sufficient because outputs are reviewed
632
01:04:20,200 --> 01:04:48,200
validated or low stakes tasks were latency matters because users interact with them in real time and tasks where data sensitivity is high because keeping processing local reduces compliance risk the third step is piloting with real production data this is where most organizations go wrong they test s l m's on synthetic benchmarks or demo data sets get mediocre results and conclude that small models don't work but synthetic data doesn't capture your document form as your terminology your templates or your edge cases
633
01:04:48,200 --> 01:05:10,200
a 5 3 model tested on generic summarization benchmarks will perform differently than the same model tested on your actual email threads run a controlled pilot select one workflow root 50% of requests to the s l m and 50% to the incumbent frontier model measure accuracy against the human reviewed gold standard measure latency and to end measure cost per thousand requests and measure user adoption
634
01:05:10,200 --> 01:05:27,200
are users still engaging with the s l m powered version or are they abandoning it for manual workarounds the research on 5 3 performance specifically highlights why production data matters for tasks involving reasoning over user provided content summarizing a meeting transcript extracting action items from an email thread
635
01:05:27,200 --> 01:05:39,200
5 3's knowledge limitations matter less because the information is in the prompt not the models training weights but for tasks requiring general world knowledge or specialized domain knowledge not present in the document the small model may struggle
636
01:05:39,200 --> 01:05:56,200
you won't know which category your task falls into until you tested with your own data the 4th step is building your routing layer this is the engineering heart of the model mixture strategy you need a classification or routing mechanism that evaluates each incoming request and directs it to the appropriate model tier
637
01:05:56,200 --> 01:06:05,200
policy based routing is the simplest approach hard rules based on data classification task type or user role if the request involves legal documents road to local s l m
638
01:06:05,200 --> 01:06:16,200
if the request is a simple summary root to local s l m if the request involves creative writing or strategic analysis root to cloud frontier model these rules are transparent auditable and easy to implement
639
01:06:16,200 --> 01:06:23,200
but they're rigid they don't adapt to task complexity that falls outside predefined categories confidence based routing is more sophisticated
640
01:06:23,200 --> 01:06:29,200
the s l m generates a response and simultaneously produces a confidence score low confidence triggers automatic escalation to the frontier model
641
01:06:29,200 --> 01:06:43,200
this approach captures edge cases that policy rules miss but it requires the s l m to be well calibrated on your specific tasks a model that is overconfident on generic benchmarks might be underconfident on your proprietary document formats or vice versa
642
01:06:43,200 --> 01:06:52,200
learned routing is the most advanced approach you train a lightweight classifier sometimes just a few hundred examples to predict which model will produce the best output for a given input
643
01:06:52,200 --> 01:07:07,200
the classifier learns from your actual production feedback where human reviewers or automated metrics score outputs from both the s l m and the frontier model over time the classifier becomes increasingly accurate at matching tasks to models, maximizing quality while minimizing cost
644
01:07:07,200 --> 01:07:16,200
the research on enterprise routing architectures documents all three approaches in production organizations typically start with policy based routing because it's implementable in weeks
645
01:07:16,200 --> 01:07:29,200
they add confidence scoring once the s l m is tuned on their data and they move to learn routing only after they have enough production feedback to train the classifier effectively the progression from simple to sophisticated mirrors how most enterprise technology adoption works
646
01:07:29,200 --> 01:07:41,200
the fifth step is department based tearing not every department in your organization has the same risk tolerance data sensitivity or compliance requirements your legal team and your finance team probably need stricter controls than your marketing team
647
01:07:41,200 --> 01:07:56,200
R&D division may have intellectual property constraints that your customer service division doesn't design your model mixture strategy with these differences in mind for high risk departments mandate local s l m processing with explicit frontier model escalation only for approved use cases
648
01:07:56,200 --> 01:08:06,200
for medium risk departments allow hybrid routing with automatic escalation for low risk departments permit broader cloud model usage while still routing routine tasks to s l m's for cost control
649
01:08:06,200 --> 01:08:27,200
the EU data boundary discussion we covered earlier feeds directly into this tearing organizations operating under strict EU residency requirements should default every department to EU only processing with local s l m's as the standard and cloud frontier models as the exception organizations with more flexible requirements can allow broader cloud usage for departments that don't handle personal data or regulated content
650
01:08:27,200 --> 01:08:56,200
the sixth step is defining your fallback and error handling no voting system is perfect there will be times when the s l m produces output that is factually wrong contextually inappropriate or simply unhelpful your architecture needs graceful degradation common patterns include automatic frontier model fallback for low confidence outputs human in the loop review for high stakes tasks and output logging for continuous quality monitoring the research on hybrid architectures emphasizes that keeping a frontier model fallback is essential the s l m handles the bulk traffic the frontier model catches the exceptions
651
01:08:56,200 --> 01:09:25,200
and the human reviewers catch the cases that neither model handles correctly the seventh step is continuous evaluation and iteration model performance isn't static your document formats change your employee behavior changes the models themselves improve through updates and new releases a model mixture strategy that works in quarter one may need adjustment by quarter three set up evaluation pipelines that regularly sample outputs from each model tier compare s l m outputs against frontier model outputs on identical inputs track cost per task latency per task
652
01:09:25,200 --> 01:09:47,200
and user satisfaction scores monitor for drift situations where the s l m performance degrades on tasks it previously handled well and maintain a backlog of tasks to migrate from frontier to s l m as the small models improve Microsoft's own roadmap supports this iterative approach the five family continues to evolve with five three point five variance already showing substantial improvements over the initial five three release
653
01:09:47,200 --> 01:10:03,200
as your AI foundry local provides model evaluation and monitoring tools that work on premises as well as in the cloud and the company's five year mission to build its own frontier models suggest that the entire model portfolio will become more capable more efficient and more tightly integrated over time
654
01:10:03,200 --> 01:10:31,200
the final point on strategy is organizational not technical someone in your organization needs to own the model mixture not the AI steering committee and aggregate but a specific team or individual with the authority to define rooting policies approve model deployments review evaluation metrics and adjust the architecture based on results without clear ownership the tier system becomes a committee consensus that defaults to the safest option which usually means rooting everything through the most capable and most expensive model
655
01:10:31,200 --> 01:10:45,200
there's also a cultural dimension to this ownership that most technology strategies overlook your employees have already formed mental models about AI capability they assume that the best model is the biggest one they may resist a tiered architecture because it feels like a downgrade
656
01:10:45,200 --> 01:10:55,200
why am I getting the cheap model while the executives get the good one this perception can undermine adoption if you don't manage it explicitly the way to manage it is through transparency and demonstration not assertion
657
01:10:55,200 --> 01:11:07,200
show uses the latency difference let them experience the instant response of a local SLM side by side with the delayed response of a cloud frontier model explain that the rooting isn't about their importance it's about the tasks requirements
658
01:11:07,200 --> 01:11:16,200
a routine summary doesn't need a trillion parameters any more than a commute to the grocery store needs a formula one car the right tool for the job is the smart choice not the expensive choice
659
01:11:16,200 --> 01:11:32,200
employee education also matters for data handling when users understand that their legal documents stay local because of compliance requirements they're more likely to accept rooting decisions that might otherwise feel arbitrary when they see that their personal data isn't being sent to another continent for processing they develop trust in the system
660
01:11:32,200 --> 01:11:41,200
that trust translates to adoption and adoption translates to the ROI that justifies the entire program the research on enterprise AI adoption patterns confirms this cultural dimension
661
01:11:41,200 --> 01:11:55,200
organizations that treat AI deployment is purely a technical rollout infrastructure licensing feature enablement see lower adoption than organizations that invest in change management user training and transparent communication about how the system works
662
01:11:55,200 --> 01:12:05,200
the model mixture strategy is no exception if your employees don't understand why they're getting a small model for one task and a large model for another they'll assume the system is broken or that they're being short-changed
663
01:12:05,200 --> 01:12:19,200
that ownership structure matters because the next 24 months will bring changes that require active decisions not passive observation the 24 month road map enterprise technology road maps are usually fiction vendors promise capabilities that slip by quarters or years
664
01:12:19,200 --> 01:12:33,200
regulatory requirements change mid cycle budget approvals lag behind technical readiness but the trajectory of SLM integration into the Microsoft ecosystem is clear enough that you can plan with reasonable confidence provided you understand what's committed
665
01:12:33,200 --> 01:12:43,200
what's probable and what speculative in the second half of twenty twenty six Microsoft's immediate priorities are expanding the infrastructure that makes local deployment practical
666
01:12:43,200 --> 01:12:51,200
Azure local is moving toward broader general availability with specific emphasis on the disconnected deployment mode for air gaped and sovereignty restricted environments
667
01:12:51,200 --> 01:12:59,200
this matters because right now many organizations can pilot local SLM's but can't fully operationalize them at scale without supported managed infrastructure
668
01:12:59,200 --> 01:13:09,200
general availability changes that equation from experimental to production ready the in country and regional inferencing rollout continues through late twenty twenty six by the end of the year
669
01:13:09,200 --> 01:13:18,200
Microsoft plans to offer in country co pilot processing in fifteen countries including regional inferencing aligned to the EU data boundary for EU and EFTA tenants
670
01:13:18,200 --> 01:13:30,200
as this capacity comes online the pressure on flex routing decreases organizations that have disabled flex routing for compliance reasons may be able to reenable it selectively confident that routine traffic stays within their region
671
01:13:30,200 --> 01:13:40,200
for EU organizations this is a significant milestone it means that even cloud hosted co pilot processing can increasingly stay within the EU reducing the gap between cloud convenience and local sovereignty
672
01:13:40,200 --> 01:13:52,200
but the fundamental architectural choice remains cloud processing in the EU is better than cloud processing outside the EU local processing in your own facility is better still because you control the hardware the logs and the data retention policy
673
01:13:52,200 --> 01:13:59,200
the in country inferencing rollout also creates an interesting intermediate option for organizations that aren't ready for full Azure local deployment
674
01:13:59,200 --> 01:14:08,200
if Microsoft offers EU based inferencing for standard co pilot tasks an organization can keep routine processing in region without managing local infrastructure
675
01:14:08,200 --> 01:14:17,200
the high sensitivity tasks can still root to Azure local SLM's and only the most complex cross jurisdictional tasks need to touch models outside the EU
676
01:14:17,200 --> 01:14:28,200
this layered approach local for highest sensitivity regional for moderate sensitivity global for lower sensitivity gives organizations a graduated path rather than a binary choice
677
01:14:28,200 --> 01:14:37,200
the five model family will continue to see incremental improvements five three point five variants are already demonstrating performance that approaches GPD for or mini on mini benchmarks
678
01:14:37,200 --> 01:14:48,200
the mixture of experts architecture in fee three point five M.O.E. shows a path forward where small models can deliver larger model capability through smarter routing of internal computation rather than brute parameter scaling
679
01:14:48,200 --> 01:14:59,200
and Microsoft's investment in its own frontier models led by Mustafa Suleiman's five year mission suggests that the entire model stack small medium and large will become more capable and more cost efficient
680
01:14:59,200 --> 01:15:07,200
the multi model ecosystem is also expanding Microsoft has already integrated anthropic explored models into parts of the co pilot ecosystem through co pilot studio
681
01:15:07,200 --> 01:15:20,200
the company maintains a reported $250 billion compute partnership with open AI and Microsoft's own MRI voice MRI image and reasoning focused models add specialized capabilities for speech vision and complex workloads
682
01:15:20,200 --> 01:15:30,200
this portfolio approach means that in 2027 your routing decisions won't just be between five three and GPD for they'll be between a dozen models optimized for specific modalities and tasks
683
01:15:30,200 --> 01:15:36,200
for M365 specifically the integration timeline points toward deeper embedding of SLM powered features
684
01:15:36,200 --> 01:15:44,200
co pilot notebooks which allow scoped intelligence over curated file sets represent a mid tier capability that benefits from local processing
685
01:15:44,200 --> 01:15:52,200
cross app orchestration where co pilot moves seamlessly between outlook teams word and excel generates more requests that benefit from low latency local handling
686
01:15:52,200 --> 01:16:05,200
and persistent co pilot identity a long term memory of user preferences writing style and project context will require both cloud synchronization and local caching to deliver responsive personalized experiences
687
01:16:05,200 --> 01:16:13,200
the bill twenty six emphasis on proving co pilot value in real production workflows rather than demos signals a maturation of the platform
688
01:16:13,200 --> 01:16:21,200
Microsoft knows that enterprise adoption in twenty twenty six and twenty seven depends on demonstrated ROI not potential capability
689
01:16:21,200 --> 01:16:27,200
that pressure works in favor of SLM adoption because SLM's make the ROI math work for the bulk of routine tasks
690
01:16:27,200 --> 01:16:37,200
the pilot deployment that costs five times less per interaction and response ten times faster is easier to justify to a CFO than one that depends on frontier models for everything
691
01:16:37,200 --> 01:16:42,200
for your organizations planning this means three concrete priorities over the next twenty four months
692
01:16:42,200 --> 01:16:52,200
first establish your evaluation infrastructure whether you use Azure AI foundry Azure AI studio or custom tooling you need the ability to benchmark models against your own data
693
01:16:52,200 --> 01:17:00,200
and cost and latency in production like conditions and compare outputs side by side this infrastructure is a prerequisite for every subsequent decision
694
01:17:00,200 --> 01:17:18,200
second build your pilot program select two to three high volume low risk workflows and run them through a model mixture architecture document the results calculate the actual savings the actual latency improvements and the actual quality delta use these pilots to build organizational confidence and secure budget for broader rollout
695
01:17:18,200 --> 01:17:38,200
third develop your governance framework define your data classification rules your routing policies your fallback procedures and your audit requirements before you scale it's much easier to design governance for a thousand users then to retrofit it for ten thousand and regulators auditors and internal risk committees will ask for documentation that is far easier to produce proactively than reactively
696
01:17:38,200 --> 01:17:58,200
the organizations that get ahead of this curve in twenty twenty six and twenty twenty seven will have a structural advantage their co pilot deployments will be cheaper faster and more compliant than competitors still routing everything through premium cloud models their IT teams will have the skills the tooling and the organizational buy-in to iterate as the model landscape evolves
697
01:17:58,200 --> 01:18:14,200
data will remain under their control regardless of how cloud provider policies change the organizations that wait will find themselves chasing a moving target co pilot costs will keep rising as usage scales latency complaints will accumulate compliance audits will reveal gaps they didn't know existed
698
01:18:14,200 --> 01:18:24,200
and when they finally decide to act they'll be starting from behind there's a competitive dynamic here that most strategic plans miss the early adopters of model mixture architectures aren't just saving money
699
01:18:24,200 --> 01:18:36,200
and the organization capability that compounds over time their teams learn how to evaluate models how to fine tune on proprietary data how to deploy on hybrid infrastructure and how to govern multi model systems
700
01:18:36,200 --> 01:18:42,200
when the next generation of models arrives whether it's five four a Microsoft build frontier model or something entirely new
701
01:18:42,200 --> 01:18:52,200
these organizations can adopt it faster because their pipeline is already built their competitors still running everything through a single cloud API have to start from scratch every time the landscape shifts
702
01:18:52,200 --> 01:19:02,200
capability advantage is particularly relevant given Microsoft's five year frontier model mission when Microsoft delivers its own general purpose frontier model the economics of the co pilot stack will change again
703
01:19:02,200 --> 01:19:10,200
a company that already runs a tiered architecture will be able to swap in the new model at the high tier without disrupting the SLM powered bulk traffic
704
01:19:10,200 --> 01:19:17,200
a company running frontier only will face yet another cost and complexity spike as they try to integrate yet another premium model
705
01:19:17,200 --> 01:19:25,200
skill scap is another factor that favors early action right now there's a shortage of engineers who understand both traditional IT infrastructure and modern AI deployment
706
01:19:25,200 --> 01:19:33,200
the people who can run Kubernetes manage GPU clusters fine tune language models and implement retrieval augmented generation pipelines are in high demand and short supply
707
01:19:33,200 --> 01:19:41,200
organizations that start building this capability in 2026 will have access to a larger talent pool and more time to train internal staff
708
01:19:41,200 --> 01:19:47,200
organizations that wait until 2028 will be competing for the same scarce talent against everyone else who finally woke up to the need
709
01:19:47,200 --> 01:19:55,200
as you are local and the associated hybrid tooling are also evolving rapidly each quarter brings new features better integration and simplified deployment patterns
710
01:19:55,200 --> 01:20:06,200
organizations that start early can grow with the platform adopting new capabilities as they mature organizations that start late will face a steeper learning curve because the platform will be more capable but also more complex
711
01:20:06,200 --> 01:20:15,200
the window for relatively simple entry is now which brings us to the bottom line because all of this architecture strategy and planning is only worthwhile if it delivers measurable value
712
01:20:15,200 --> 01:20:24,200
the real ROI of SLM's in enterprise return on investment for AI initiatives is notoriously difficult to calculate vendor sell potential finance teams demand proof
713
01:20:24,200 --> 01:20:33,200
and the gap between pilot success and production value is where most AI projects die so let's be specific about what small language models actually deliver in terms that survive a board level review
714
01:20:33,200 --> 01:20:46,200
the most direct ROI is cost reduction organizations running tiered architectures with SLM's handling routine traffic report 40 to 90% reductions in total LLM spend compared to frontier only designs that isn't a minor optimization
715
01:20:46,200 --> 01:20:54,200
for an enterprise spending six or seven figures annually on AI inference a 50% reduction is material it frees budget for other initiatives
716
01:20:54,200 --> 01:21:02,200
it extends the runway of AI programs that might otherwise face cuts and it transforms the conversation from AI is expensive to AI is efficient
717
01:21:02,200 --> 01:21:16,200
to make this concrete consider a mid-market enterprise with 1000 co-pilot users if each user generates an average of 20 requests per day and each request consumes roughly 2000 tokens of combined input and output the monthly token volume is 40 million
718
01:21:16,200 --> 01:21:28,200
at GPT-4O blended rates that's approximately 160,000 dollars per year in inference costs alone switching routine tasks to an SLM at one tenth the cost reduces that line item to 16,000 dollars
719
01:21:28,200 --> 01:21:40,200
the 144,000 dollar difference pays for an additional full-time AI infrastructure engineer a local GPU server and the operational tooling to manage the hybrid architecture with budget left over
720
01:21:40,200 --> 01:21:49,200
the research on enterprise cost analysis frames this as a shift in AI adoption maturity early pilots favor large models because they minimize engineering effort and maximize capability
721
01:21:49,200 --> 01:22:06,200
a production systems increasingly optimized for unit economics latency and governance the market is moving towards specialized model portfolios rather than single universal models and the organizations that make this shift early capture the cost advantage before their competitors even recognize the option exists latency reduction delivers a different kind of ROI
722
01:22:06,200 --> 01:22:15,200
user adoption a co-pilot feature that responds in under 100 milliseconds feels like a native part of the application a feature that takes two seconds feels like a separate system
723
01:22:15,200 --> 01:22:28,200
the difference in user behavior is dramatic employees integrate fast tools into their muscle memory they avoid slow tools after the third frustrating delay and adoption metrics are what finance committees look at when deciding whether to renew licenses or expand deployment
724
01:22:28,200 --> 01:22:42,200
the research on latency benchmarks makes the user experience case explicitly SLM's on edge hardware deliver 10 to 50 millisecond responses cloud LLM deliver 300 to 2000 milliseconds that isn't a technical detail that only engineers care about
725
01:22:42,200 --> 01:22:56,200
it's the difference between a tool that becomes habit and a tool that becomes shelf where sovereignty and compliance ROI is harder to quantify but equally real avoiding a regulatory fine or a data breach is worth more than any cost optimization
726
01:22:56,200 --> 01:23:03,200
enabling AI capabilities in jurisdictions where cloud processing is legally restricted opens markets and use cases that would otherwise remain blocked
727
01:23:03,200 --> 01:23:14,200
and the internal confidence that comes from knowing your data never left your facility is a qualitative benefit that shows up in faster decision making broader deployment approvals and reduced risk committee friction
728
01:23:14,200 --> 01:23:31,200
the EU data boundary research we reviewed earlier highlights this in concrete terms organizations that disable flex routing block and throttic models and root sensitive processing to local infrastructure avoid international transfer assessments legal review cycles and the operational overhead of managing cross border data flows
729
01:23:31,200 --> 01:23:47,200
organizations in regulated sectors like finance healthcare and government this isn't a nice to have it's a prerequisite for operation but there's a hidden ROI that most cost analyses miss developer velocity and shadow IT reduction when your official AI platform is slow, expensive and hard to govern employees find alternatives
730
01:23:47,200 --> 01:23:58,200
they use personal accounts with public AI services they copy sensitive documents into unauthorized tools because the approved tool is too painful to use they build departmental workarounds that bypass IT entirely
731
01:23:58,200 --> 01:24:09,200
this shadow AI usage is invisible to cost reports and compliance audits until it becomes a breach or a leak a fast affordable well-governed model mixture architecture brings that usage back into the light
732
01:24:09,200 --> 01:24:20,200
employees use the official platform because it's the best option not because it's the only permitted option IT maintains visibility and control and the organization captures the productivity benefits without the compliance risks
733
01:24:20,200 --> 01:24:34,200
Microsoft's own positioning of SLM supports this interpretation the company describes small models as ideal for scenarios where efficiency and device local deployment matter and emphasizes their role in hybrid architectures alongside cloud delivered co pilot
734
01:24:34,200 --> 01:24:41,200
this isn't Microsoft hedging its bets it's Microsoft acknowledging that the future of enterprise AI is distributed tiered and context sensitive
735
01:24:41,200 --> 01:24:52,200
the total ROI picture combines all of these factors direct cost savings on inference indirect savings from higher adoption and lower support overhead risk reduction from local processing and stronger governance
736
01:24:52,200 --> 01:25:01,200
and strategic positioning from having an AI architecture that scales with usage rather than choking on it there's one more ROI dimension that deserves attention the environmental argument
737
01:25:01,200 --> 01:25:09,200
large language models consume enormous amounts of electricity a single frontier model inference request might use enough energy to power a light bulb for an hour
738
01:25:09,200 --> 01:25:29,200
the request is multiplied by millions of daily interactions across thousands of enterprises the aggregate environmental impact is significant small language models by virtue of their efficient architecture use a fraction of the energy per request for organizations with carbon reduction commitments or for organizations in jurisdictions with emissions reporting requirements the energy efficiency of SLM is not a side benefit
739
01:25:29,200 --> 01:25:42,200
it's a compliance and reputation consideration the research on enterprise AI cost drivers notes that SLM require fewer resources than LLM's reducing compute and energy consumption while still providing high utility for domain specific tasks
740
01:25:42,200 --> 01:25:50,200
in an era where data center emissions are under increasing scrutiny from regulators investors and customers this efficiency advantage will only grow in importance
741
01:25:50,200 --> 01:26:16,200
a sustainability officer asking about the carbon footprint of your AI deployment will find a much better story to tell with SLM's handling 80% of the workload for the IT leader pitching this to the board the framing is straightforward we can continue paying premium prices for every AI request watching adoption plateau because users won't wait managing an expanding compliance surface area as cloud routing options multiply and consuming energy at rates that undermine our sustainability commitments
742
01:26:16,200 --> 01:26:32,200
or we can build a tiered architecture that matches the right model to each task delivering faster responses at lower cost with stronger data control and reduced environmental impact the technology exists the benchmarks exist and the deployment patterns exist the only question is whether we lead the transition or follow it
743
01:26:32,200 --> 01:26:39,200
and that's exactly where this conversation lands because the flow we've been diagnosing isn't a product bug it's an architectural assumption and assumptions are choices
744
01:26:39,200 --> 01:26:55,200
the organizations that thrive in the next phase of enterprise AI won't be the ones with the biggest models they'll be the ones with the smartest architecture a tiered system where small language models handle the routine work locally cheaply and privately while frontier models stay in reserve for the exceptions that actually need them
745
01:26:55,200 --> 01:27:07,200
that's the SLM revolution and it's not coming it's already here every day you wait your co pilot costs climb your compliance surface expands and your users grow more frustrated with tools that promise intelligence but deliver delays
746
01:27:07,200 --> 01:27:27,200
the architecture to fix this exists the models exist and the deployment patterns exist the only missing piece is the decision to stop accepting a broken assumption and start building a smarter system if this changed how you think about co pilot and AI architecture follow me my co-peters on LinkedIn for more deep dives on Microsoft 365 Azure and the systems behind modern work

Founder of m365.fm, m365.show and m365con.net
Mirko Peters is a Microsoft 365 expert, content creator, and founder of m365.fm, a platform dedicated to sharing practical insights on modern workplace technologies. His work focuses on Microsoft 365 governance, security, collaboration, and real-world implementation strategies.
Through his podcast and written content, Mirko provides hands-on guidance for IT professionals, architects, and business leaders navigating the complexities of Microsoft 365. He is known for translating complex topics into clear, actionable advice, often highlighting common mistakes and overlooked risks in real-world environments.
With a strong emphasis on community contribution and knowledge sharing, Mirko is actively building a platform that connects experts, shares experiences, and helps organizations get the most out of their Microsoft 365 investments.